


UX And Product Designer’s Career Paths In 2026
How to shape your career path for 2026, with decision trees for designers and a UX skills self-assessment matrix. The only limits for tomorrow are the doubts we have today. Brought to you by Smart Int
Ux
From Prompt To Partner: Designing Your Custom AI Assistant
What if your best AI prompts didn’t disappear into your unorganized chat history, but came back tomorrow as a reliable assistant? In this article, you’ll learn how to turn one-off “aha” prompt
Ux
Generating Unique Random Numbers In JavaScript Using Sets
Want to create more randomized effects in your JavaScript code? The Math.random() method alone, with its limitations, won’t cut it for generating unique random numbers. Amejimaobari Ollornwi explain
Javascript

Intent Prototyping: The Allure And Danger Of Pure Vibe Coding In Enterprise UX (Part 1)
Intent Prototyping: The Allure And Danger Of Pure Vibe Coding In Enterprise UX (Part 1) Intent Prototyping: The Allure And Danger Of Pure Vibe Coding In Enterprise UX (Part 1) Yegor Gilyov 2025-09-24T17:00:00+00:00 2025-10-01T15:02:43+00:00 There is a spectrum of opinions on how dramatically all creative […]
Accessibility
Intent Prototyping: The Allure And Danger Of Pure Vibe Coding In Enterprise UX (Part 1)
Yegor Gilyov 2025-09-24T17:00:00+00:00
2025-10-01T15:02:43+00:00
There is a spectrum of opinions on how dramatically all creative professions will be changed by the coming wave of agentic AI, from the very skeptical to the wildly optimistic and even apocalyptic. I think that even if you are on the “skeptical” end of the spectrum, it makes sense to explore ways this new technology can help with your everyday work. As for my everyday work, I’ve been doing UX and product design for about 25 years now, and I’m always keen to learn new tricks and share them with colleagues. Right now, I’m interested in AI-assisted prototyping, and I’m here to share my thoughts on how it can change the process of designing digital products.
To set your expectations up front: this exploration focuses on a specific part of the product design lifecycle. Many people know about the Double Diamond framework, which shows the path from problem to solution. However, I think it’s the Triple Diamond model that makes an important point for our needs. It explicitly separates the solution space into two phases: Solution Discovery (ideating and validating the right concept) and Solution Delivery (engineering the validated concept into a final product). This article is focused squarely on that middle diamond: Solution Discovery.
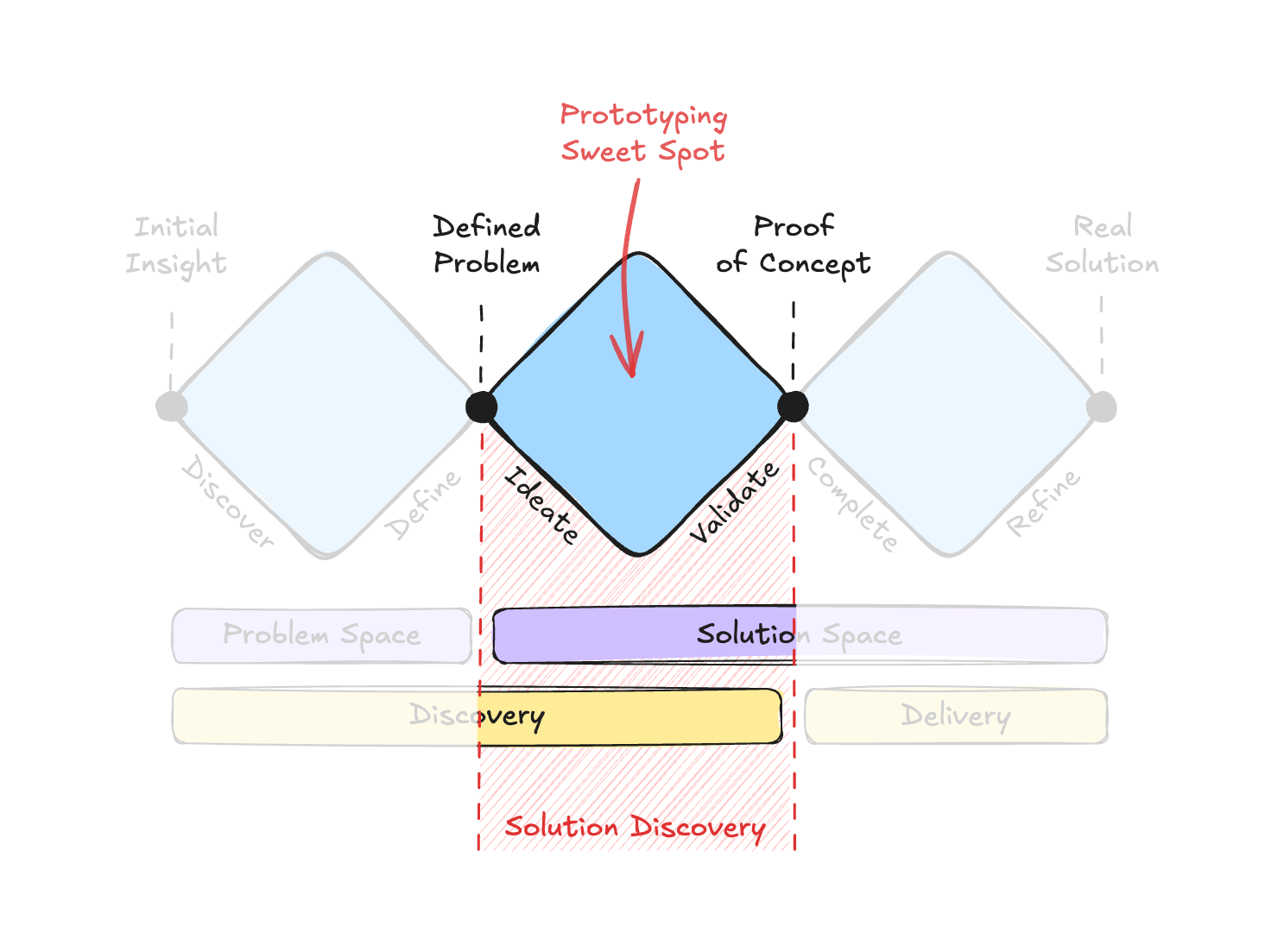{kind=link}
How AI can help with the preceding (Problem Discovery) and the following (Solution Delivery) stages is out of the scope of this article. Problem Discovery is less about prototyping and more about research, and while I believe AI can revolutionize the research process as well, I’ll leave that to people more knowledgeable in the field. As for Solution Delivery, it is more about engineering optimization. There’s no doubt that software engineering in the AI era is undergoing dramatic changes, but I’m not an engineer — I’m a designer, so let me focus on my “sweet spot”.
And my “sweet spot” has a specific flavor: designing enterprise applications. In this world, the main challenge is taming complexity: dealing with complicated data models and guiding users through non-linear workflows. This background has had a big impact on my approach to design, putting a lot of emphasis on the underlying logic and structure. This article explores the potential of AI through this lens.
I’ll start by outlining the typical artifacts designers create during Solution Discovery. Then, I’ll examine the problems with how this part of the process often plays out in practice. Finally, we’ll explore whether AI-powered prototyping can offer a better approach, and if so, whether it aligns with what people call “vibe coding,” or calls for a more deliberate and disciplined way of working.
What We Create During Solution Discovery
The Solution Discovery phase begins with the key output from the preceding research: a well-defined problem and a core hypothesis for a solution. This is our starting point. The artifacts we create from here are all aimed at turning that initial hypothesis into a tangible, testable concept.
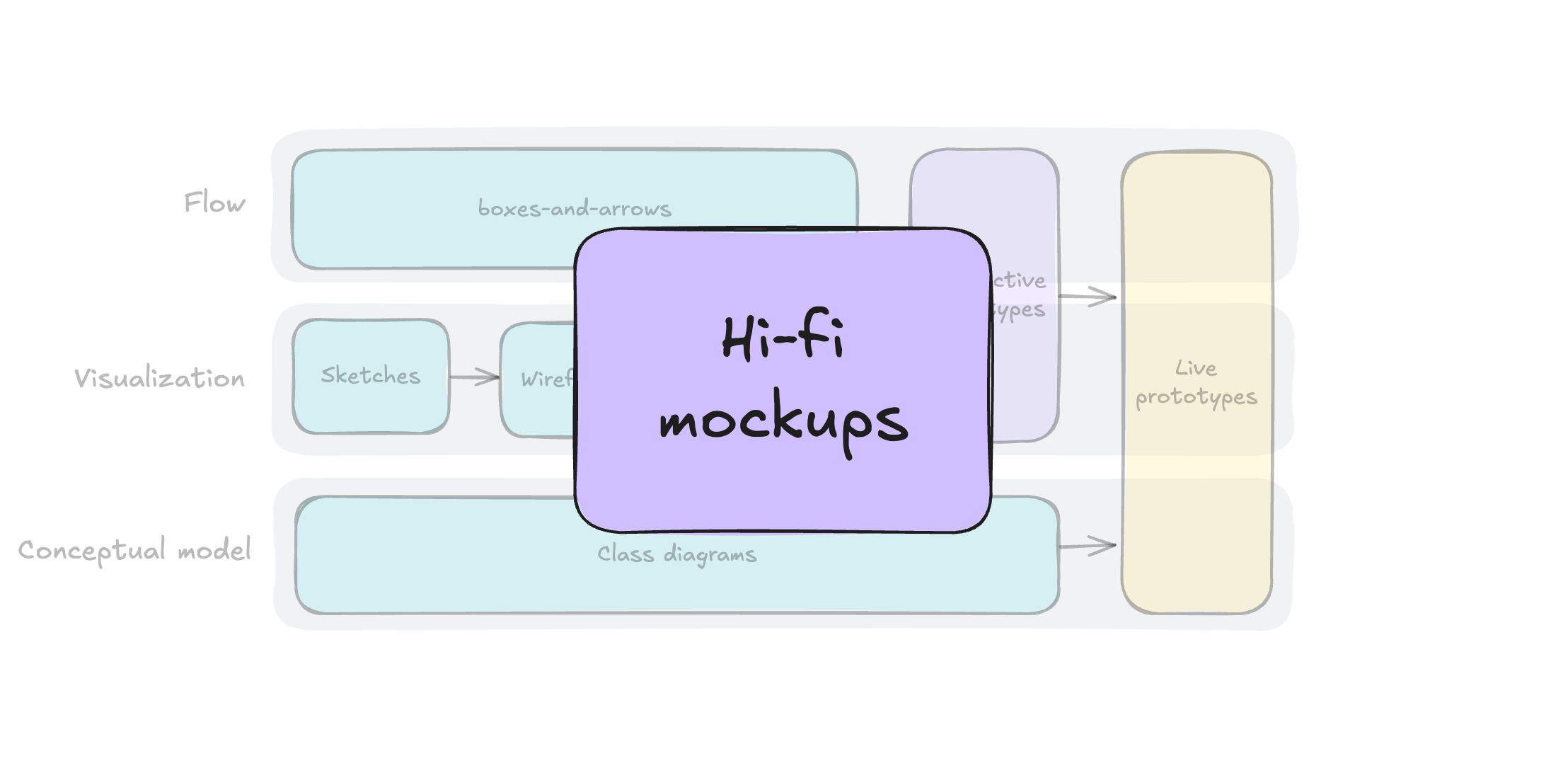
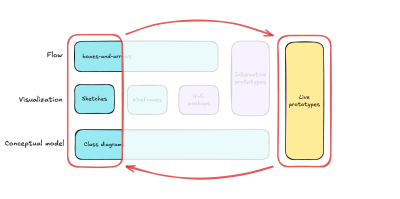
Traditionally, at this stage, designers can produce artifacts of different kinds, progressively increasing fidelity: from napkin sketches, boxes-and-arrows, and conceptual diagrams to hi-fi mockups, then to interactive prototypes, and in some cases even live prototypes. Artifacts of lower fidelity allow fast iteration and enable the exploration of many alternatives, while artifacts of higher fidelity help to understand, explain, and validate the concept in all its details.
It’s important to think holistically, considering different aspects of the solution. I would highlight three dimensions:
- Conceptual model: Objects, relations, attributes, actions;
- Visualization: Screens, from rough sketches to hi-fi mockups;
- Flow: From the very high-level user journeys to more detailed ones.
One can argue that those are layers rather than dimensions, and each of them builds on the previous ones (for example, according to Semantic IxD by Daniel Rosenberg), but I see them more as different facets of the same thing, so the design process through them is not necessarily linear: you may need to switch from one perspective to another many times.
This is how different types of design artifacts map to these dimensions:
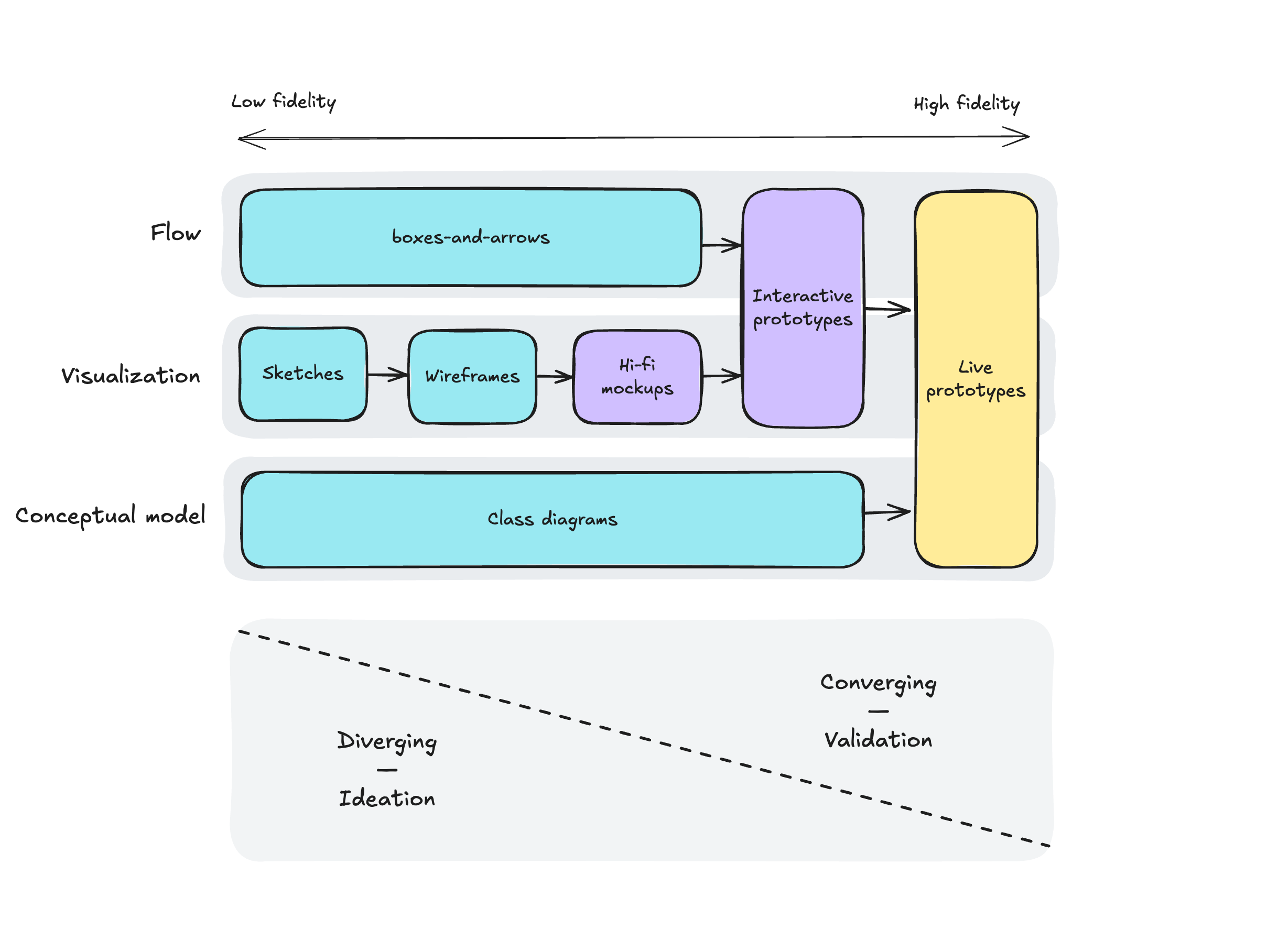{kind=link}
As Solution Discovery progresses, designers move from the left part of this map to the right, from low-fidelity to high-fidelity, from ideating to validating, from diverging to converging.
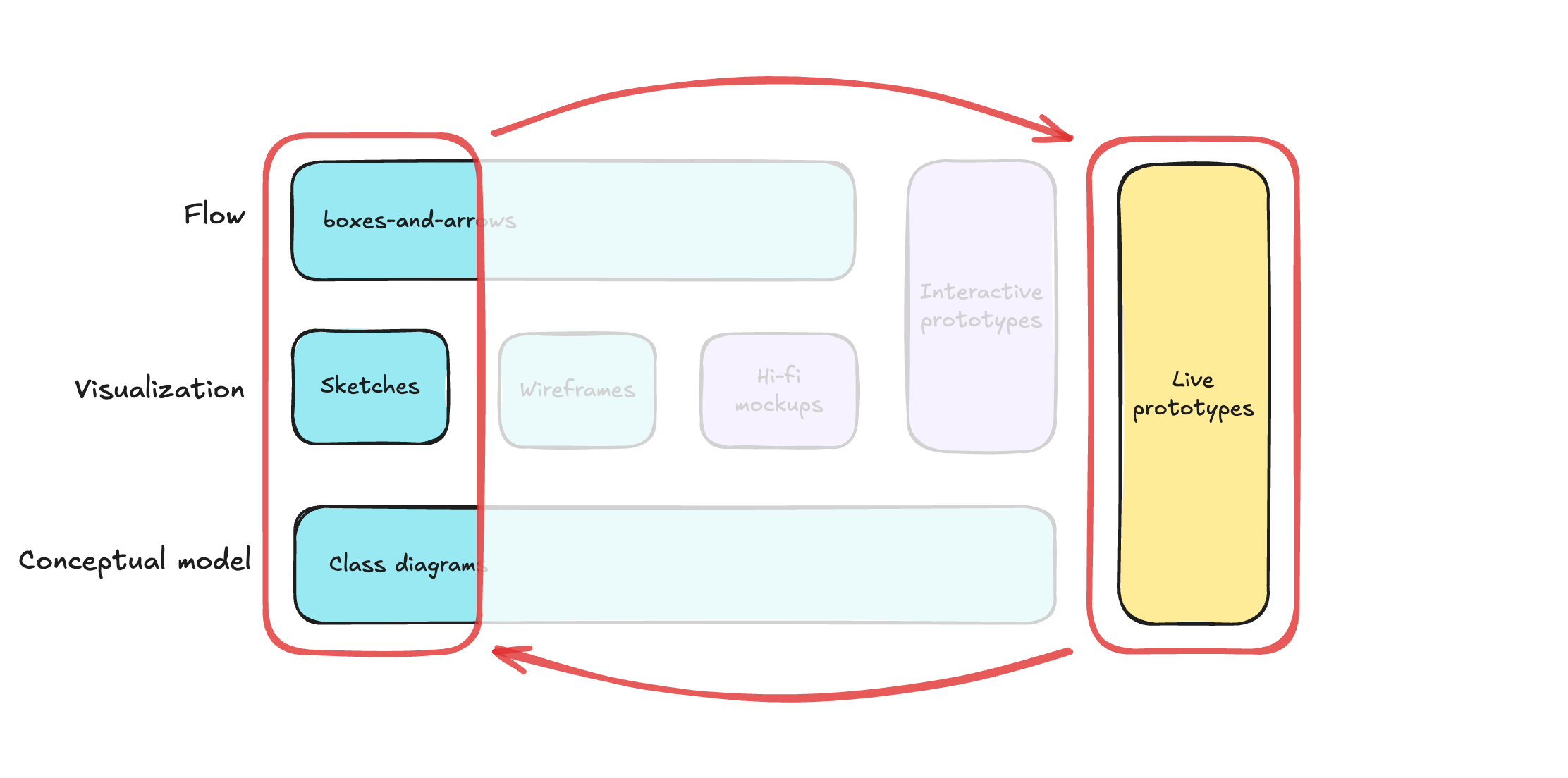
Note that at the beginning of the process, different dimensions are supported by artifacts of different types (boxes-and-arrows, sketches, class diagrams, etc.), and only closer to the end can you build a live prototype that encompasses all three dimensions: conceptual model, visualization, and flow.
This progression shows a classic trade-off, like the difference between a pencil drawing and an oil painting. The drawing lets you explore ideas in the most flexible way, whereas the painting has a lot of detail and overall looks much more realistic, but is hard to adjust. Similarly, as we go towards artifacts that integrate all three dimensions at higher fidelity, our ability to iterate quickly and explore divergent ideas goes down. This inverse relationship has long been an accepted, almost unchallenged, limitation of the design process.
The Problem With The Mockup-Centric Approach
Faced with this difficult trade-off, often teams opt for the easiest way out. On the one hand, they need to show that they are making progress and create things that appear detailed. On the other hand, they rarely can afford to build interactive or live prototypes. This leads them to over-invest in one type of artifact that seems to offer the best of both worlds. As a result, the neatly organized “bento box” of design artifacts we saw previously gets shrunk down to just one compartment: creating static high-fidelity mockups.
{kind=link}
This choice is understandable, as several forces push designers in this direction. Stakeholders are always eager to see nice pictures, while artifacts representing user flows and conceptual models receive much less attention and priority. They are too high-level and hardly usable for validation, and usually, not everyone can understand them.
On the other side of the fidelity spectrum, interactive prototypes require too much effort to create and maintain, and creating live prototypes in code used to require special skills (and again, effort). And even when teams make this investment, they do so at the end of Solution Discovery, during the convergence stage, when it is often too late to experiment with fundamentally different ideas. With so much effort already sunk, there is little appetite to go back to the drawing board.
It’s no surprise, then, that many teams default to the perceived safety of static mockups, seeing them as a middle ground between the roughness of the sketches and the overwhelming complexity and fragility that prototypes can have.
As a result, validation with users doesn’t provide enough confidence that the solution will actually solve the problem, and teams are forced to make a leap of faith to start building. To make matters worse, they do so without a clear understanding of the conceptual model, the user flows, and the interactions, because from the very beginning, designers’ attention has been heavily skewed toward visualization.
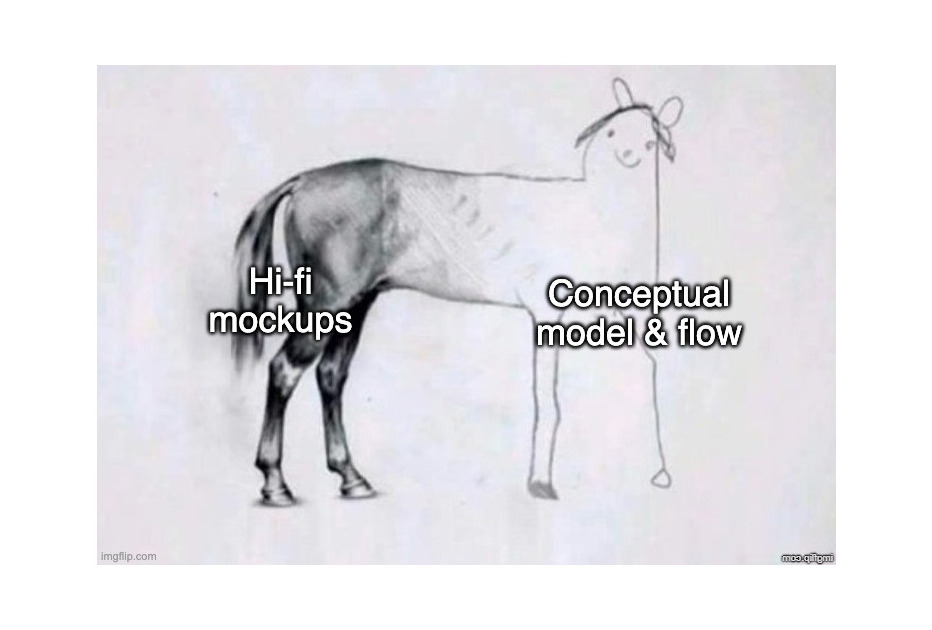
The result is often a design artifact that resembles the famous “horse drawing” meme: beautifully rendered in the parts everyone sees first (the mockups), but dangerously underdeveloped in its underlying structure (the conceptual model and flows).
{kind=link}

While this is a familiar problem across the industry, its severity depends on the nature of the project. If your core challenge is to optimize a well-understood, linear flow (like many B2C products), a mockup-centric approach can be perfectly adequate. The risks are contained, and the “lopsided horse” problem is unlikely to be fatal.
However, it’s different for the systems I specialize in: complex applications defined by intricate data models and non-linear, interconnected user flows. Here, the biggest risks are not on the surface but in the underlying structure, and a lack of attention to the latter would be a recipe for disaster.
Transforming The Design Process
This situation makes me wonder:
How might we close the gap between our design intent and a live prototype, so that we can iterate on real functionality from day one?
“
{kind=link}
If we were able to answer this question, we would:
- Learn faster.
By going straight from intent to a testable artifact, we cut the feedback loop from weeks to days. - Gain more confidence.
Users interact with real logic, which gives us more proof that the idea works. - Enforce conceptual clarity.
A live prototype cannot hide a flawed or ambiguous conceptual model. - Establish a clear and lasting source of truth.
A live prototype, combined with a clearly documented design intent, provides the engineering team with an unambiguous specification.
Of course, the desire for such a process is not new. This vision of a truly prototype-driven workflow is especially compelling for enterprise applications, where the benefits of faster learning and forced conceptual clarity are the best defense against costly structural flaws. But this ideal was still out of reach because prototyping in code took so much work and specialized talents. Now, the rise of powerful AI coding assistants changes this equation in a big way.
The Seductive Promise Of “Vibe Coding”
And the answer seems to be obvious: vibe coding!
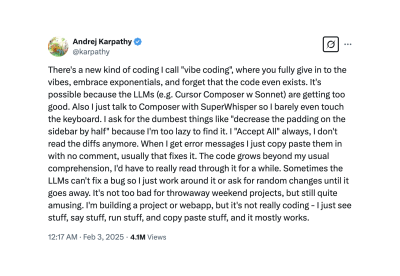
“Vibe coding is an artificial intelligence-assisted software development style popularized by Andrej Karpathy in early 2025. It describes a fast, improvisational, collaborative approach to creating software where the developer and a large language model (LLM) tuned for coding is acting rather like pair programmers in a conversational loop.”
The original tweet by Andrej Karpathy:
{kind=link}
The allure of this approach is undeniable. If you are not a developer, you are bound to feel awe when you describe a solution in plain language, and moments later, you can interact with it. This seems to be the ultimate fulfillment of our goal: a direct, frictionless path from an idea to a live prototype. But is this method reliable enough to build our new design process around it?
The Trap: A Process Without A Blueprint
Vibe coding mixes up a description of the UI with a description of the system itself, resulting in a prototype based on changing assumptions rather than a clear, solid model.
The pitfall of vibe coding is that it encourages us to express our intent in the most ambiguous way possible: by having a conversation.
“
This is like hiring a builder and telling them what to do one sentence at a time without ever presenting them a blueprint. They could make a wall that looks great, but you can’t be sure that it can hold weight.
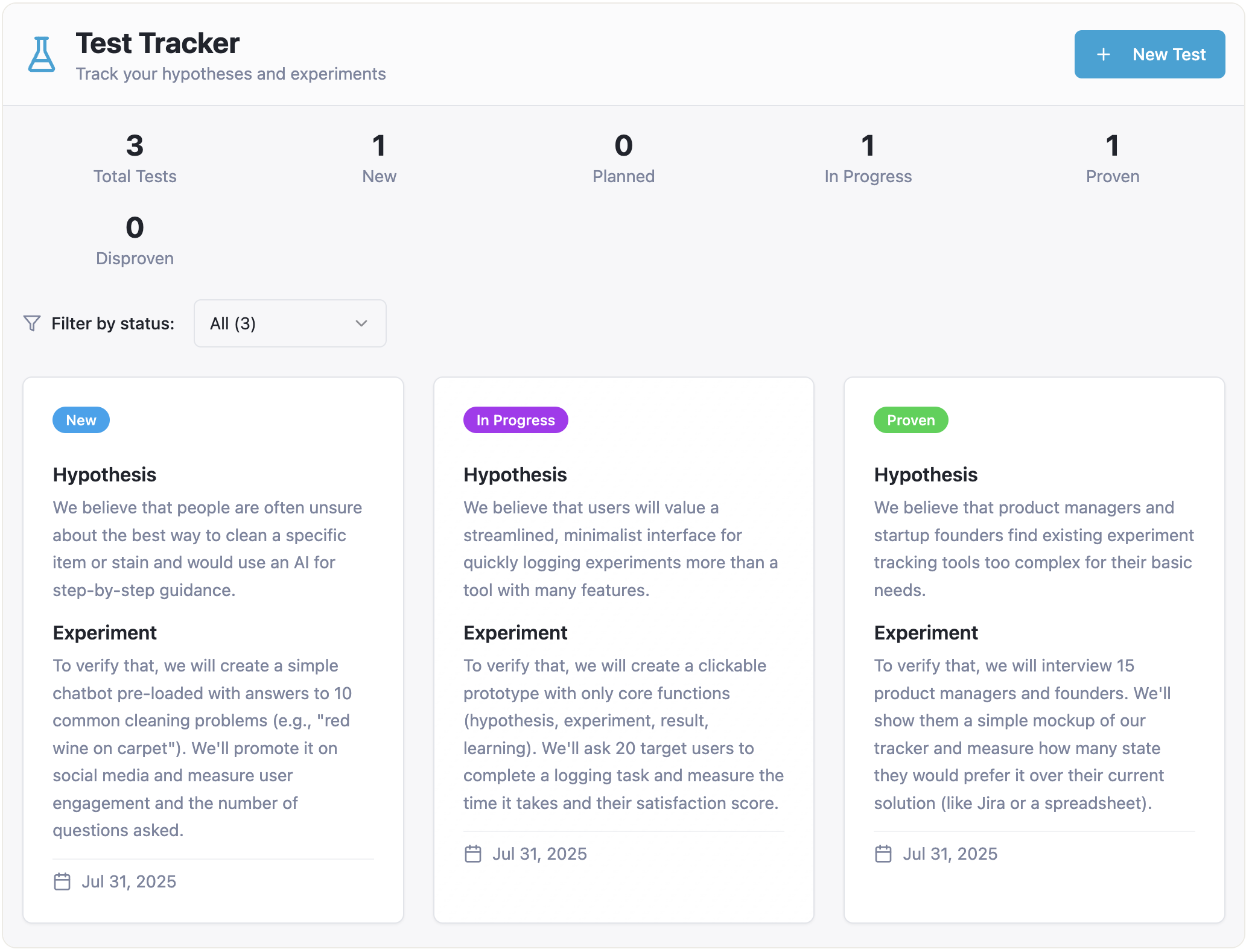
I’ll give you one example illustrating problems you may face if you try to jump over the chasm between your idea and a live prototype relying on pure vibe coding in the spirit of Andrej Karpathy’s tweet. Imagine I want to prototype a solution to keep track of tests to validate product ideas. I open my vibe coding tool of choice (I intentionally don’t disclose its name, as I believe they all are awesome yet prone to similar pitfalls) and start with the following prompt:
I need an app to track tests. For every test, I need to fill out the following data:
- Hypothesis (we believe that...)
- Experiment (to verify that, we will...)
- When (a single date, or a period)
- Status (New/Planned/In Progress/Proven/Disproven)
And in a minute or so, I get a working prototype:
{kind=link}
![]()
Inspired by success, I go further:
Please add the ability to specify a product idea for every test. Also, I want to filter tests by product ideas and see how many tests each product idea has in each status.
And the result is still pretty good:
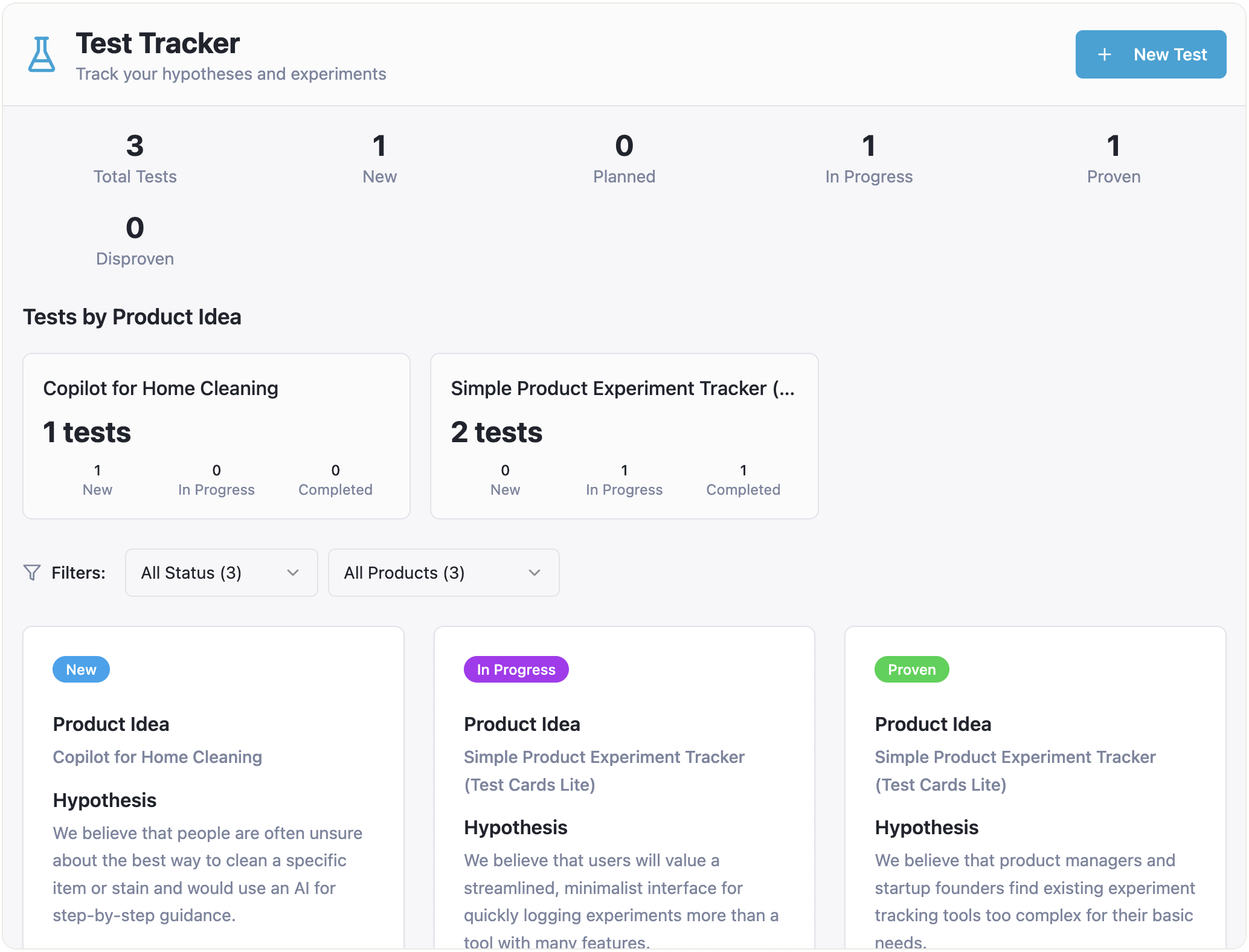{kind=link}
![]()
But then I want to extend the functionality related to product ideas:
Okay, one more thing. For every product idea, I want to assess the impact score, the confidence score, and the ease score, and get the overall ICE score. Perhaps I need a separate page focused on the product idea, with all the relevant information and related tests.
And from this point on, the results are getting more and more confusing.
The flow of creating tests hasn’t changed much. I can still create a bunch of tests, and they seem to be organized by product ideas. But when I click “Product Ideas” in the top navigation, I see nothing:
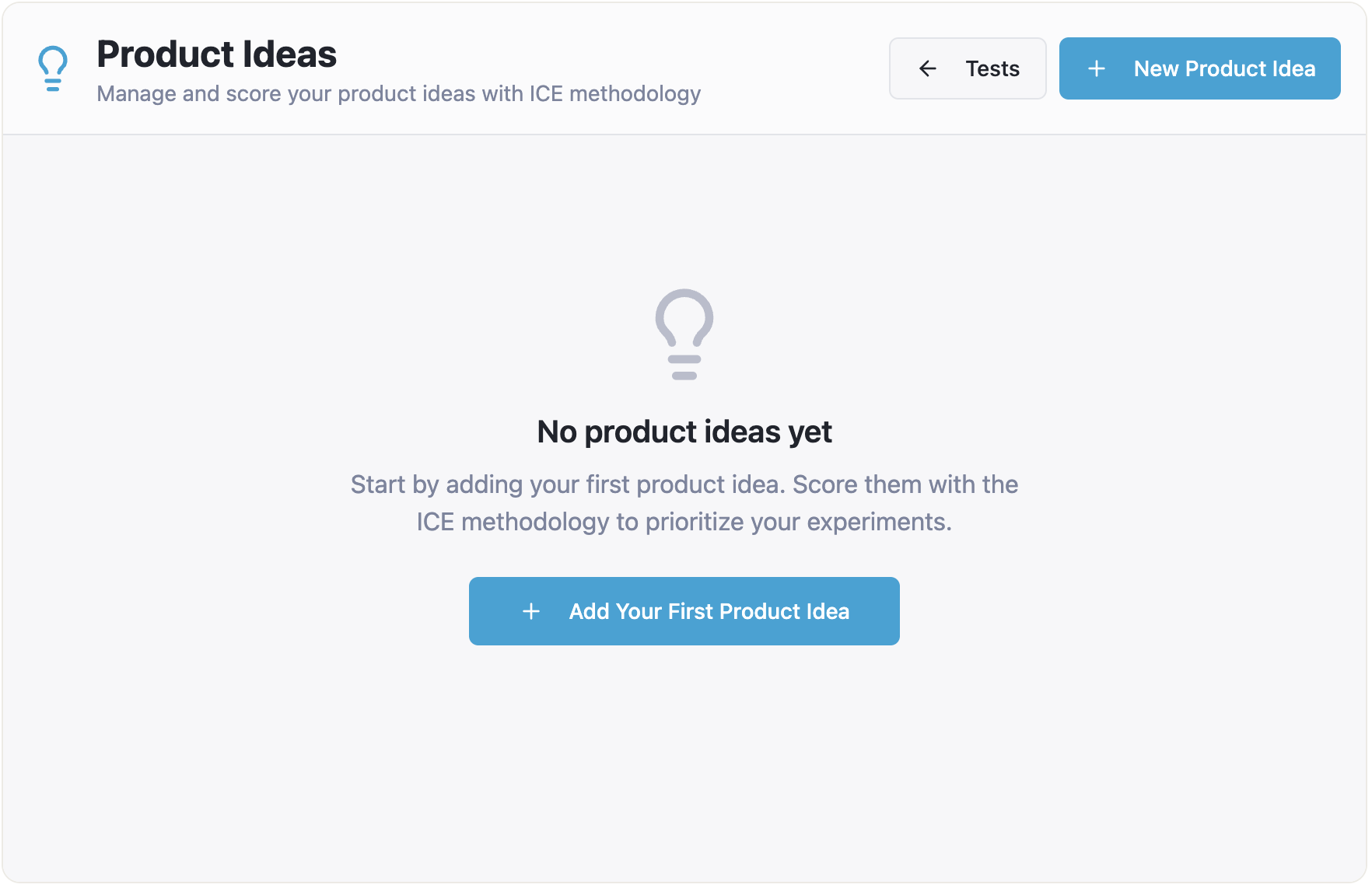{kind=link}
I need to create my ideas from scratch, and they are not connected to the tests I created before:
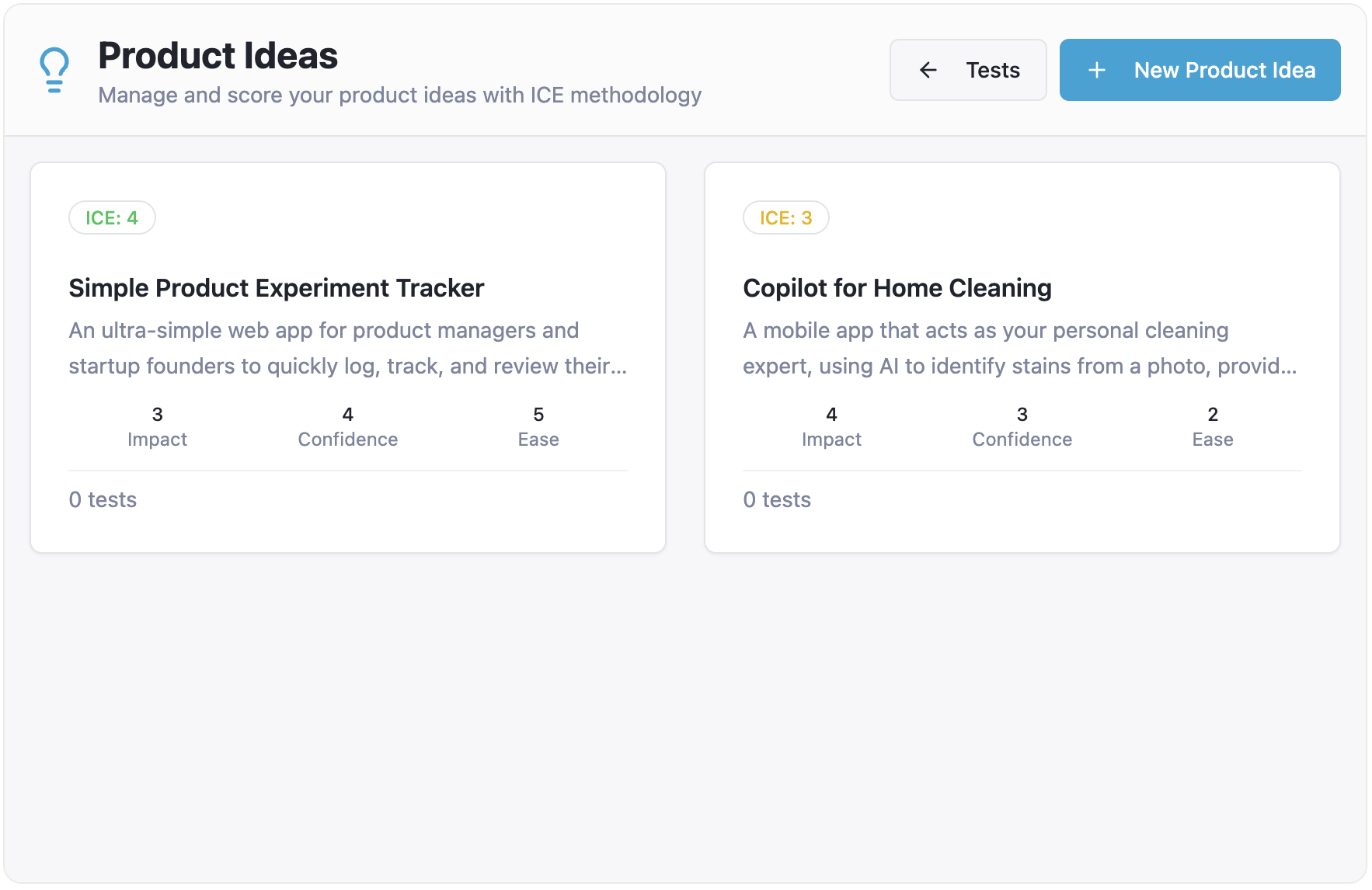{kind=link}
Moreover, when I go back to “Tests”, I see that they are all gone. Clearly something went wrong, and my AI assistant confirms that:
No, this is not expected behavior — it’s a bug! The issue is that tests are being stored in two separate places (local state in the Index page and App state), so tests created on the main page don’t sync with the product ideas page.
Sure, eventually it fixed that bug, but note that we encountered this just on the third step, when we asked to slightly extend the functionality of a very simple app. The more layers of complexity we add, the more roadblocks of this sort we are bound to face.
Also note that this specific problem of a not fully thought-out relationship between two entities (product ideas and tests) is not isolated at the technical level, and therefore, it didn’t go away once the technical bug was fixed. The underlying conceptual model is still broken, and it manifests in the UI as well.
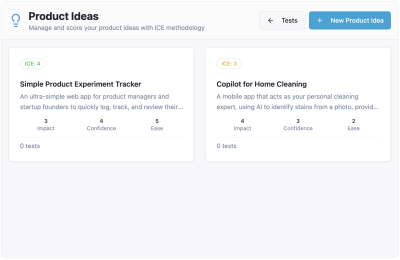
For example, you can still create “orphan” tests that are not connected to any item from the “Product Ideas” page. As a result, you may end up with different numbers of ideas and tests on different pages of the app:
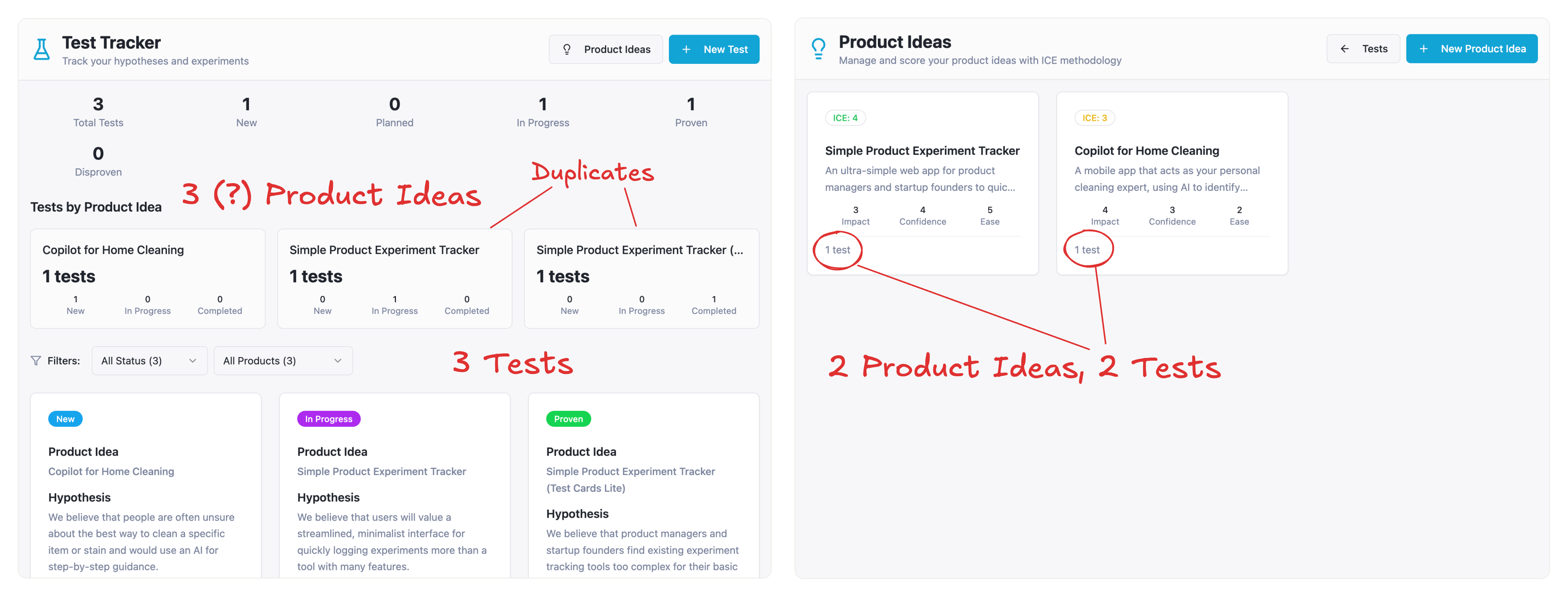{kind=link}

Let’s diagnose what really happened here. The AI’s response that this is a “bug” is only half the story. The true root cause is a conceptual model failure. My prompts never explicitly defined the relationship between product ideas and tests. The AI was forced to guess, which led to the broken experience. For a simple demo, this might be a fixable annoyance. But for a data-heavy enterprise application, this kind of structural ambiguity is fatal. It demonstrates the fundamental weakness of building without a blueprint, which is precisely what vibe coding encourages.
Don’t take this as a criticism of vibe coding tools. They are creating real magic. However, the fundamental truth about “garbage in, garbage out” is still valid. If you don’t express your intent clearly enough, chances are the result won’t fulfill your expectations.
Another problem worth mentioning is that even if you wrestle it into a state that works, the artifact is a black box that can hardly serve as reliable specifications for the final product. The initial meaning is lost in the conversation, and all that’s left is the end result. This makes the development team “code archaeologists,” who have to figure out what the designer was thinking by reverse-engineering the AI’s code, which is frequently very complicated. Any speed gained at the start is lost right away because of this friction and uncertainty.
From Fast Magic To A Solid Foundation
Pure vibe coding, for all its allure, encourages building without a blueprint. As we’ve seen, this results in structural ambiguity, which is not acceptable when designing complex applications. We are left with a seemingly quick but fragile process that creates a black box that is difficult to iterate on and even more so to hand off.
This leads us back to our main question: how might we close the gap between our design intent and a live prototype, so that we can iterate on real functionality from day one, without getting caught in the ambiguity trap? The answer lies in a more methodical, disciplined, and therefore trustworthy process.
In Part 2 of this series, “A Practical Guide to Building with Clarity”, I will outline the entire workflow for Intent Prototyping. This method places the explicit intent of the designer at the forefront of the process while embracing the potential of AI-assisted coding.
Thank you for reading, and I look forward to seeing you in Part 2.
(yk)

The Psychology Of Trust In AI: A Guide To Measuring And Designing For User Confidence
The Psychology Of Trust In AI: A Guide To Measuring And Designing For User Confidence The Psychology Of Trust In AI: A Guide To Measuring And Designing For User Confidence Victor Yocco 2025-09-19T10:00:00+00:00 2025-09-24T15:02:52+00:00 Misuse and misplaced trust of AI is becoming an unfortunate common […]
Accessibility
The Psychology Of Trust In AI: A Guide To Measuring And Designing For User Confidence
Victor Yocco 2025-09-19T10:00:00+00:00
2025-09-24T15:02:52+00:00
Misuse and misplaced trust of AI is becoming an unfortunate common event. For example, lawyers trying to leverage the power of generative AI for research submit court filings citing multiple compelling legal precedents. The problem? The AI had confidently, eloquently, and completely fabricated the cases cited. The resulting sanctions and public embarrassment can become a viral cautionary tale, shared across social media as a stark example of AI’s fallibility.
This goes beyond a technical glitch; it’s a catastrophic failure of trust in AI tools in an industry where accuracy and trust are critical. The trust issue here is twofold — the law firms are submitting briefs in which they have blindly over-trusted the AI tool to return accurate information. The subsequent fallout can lead to a strong distrust in AI tools, to the point where platforms featuring AI might not be considered for use until trust is reestablished.
Issues with trusting AI aren’t limited to the legal field. We are seeing the impact of fictional AI-generated information in critical fields such as healthcare and education. On a more personal scale, many of us have had the experience of asking Siri or Alexa to perform a task, only to have it done incorrectly or not at all, for no apparent reason. I’m guilty of sending more than one out-of-context hands-free text to an unsuspecting contact after Siri mistakenly pulls up a completely different name than the one I’d requested.
{kind=link}

With digital products moving to incorporate generative and agentic AI at an increasingly frequent rate, trust has become the invisible user interface. When it works, our interactions are seamless and powerful. When it breaks, the entire experience collapses, with potentially devastating consequences. As UX professionals, we’re on the front lines of a new twist on a common challenge. How do we build products that users can rely on? And how do we even begin to measure something as ephemeral as trust in AI?
Trust isn’t a mystical quality. It is a psychological construct built on predictable factors. I won’t dive deep into academic literature on trust in this article. However, it is important to understand that trust is a concept that can be understood, measured, and designed for. This article will provide a practical guide for UX researchers and designers. We will briefly explore the psychological anatomy of trust, offer concrete methods for measuring it, and provide actionable strategies for designing more trustworthy and ethical AI systems.
The Anatomy of Trust: A Psychological Framework for AI
To build trust, we must first understand its components. Think of trust like a four-legged stool. If any one leg is weak, the whole thing becomes unstable. Based on classic psychological models, we can adapt these “legs” for the AI context.
1. Ability (or Competence)
This is the most straightforward pillar: Does the AI have the skills to perform its function accurately and effectively? If a weather app is consistently wrong, you stop trusting it. If an AI legal assistant creates fictitious cases, it has failed the basic test of ability. This is the functional, foundational layer of trust.
2. Benevolence
This moves from function to intent. Does the user believe the AI is acting in their best interest? A GPS that suggests a toll-free route even if it’s a few minutes longer might be perceived as benevolent. Conversely, an AI that aggressively pushes sponsored products feels self-serving, eroding this sense of benevolence. This is where user fears, such as concerns about job displacement, directly challenge trust—the user starts to believe the AI is not on their side.
3. Integrity
Does AI operate on predictable and ethical principles? This is about transparency, fairness, and honesty. An AI that clearly states how it uses personal data demonstrates integrity. A system that quietly changes its terms of service or uses dark patterns to get users to agree to something violates integrity. An AI job recruiting tool that has subtle yet extremely harmful social biases, existing in the algorithm, violates integrity.
4. Predictability & Reliability
Can the user form a stable and accurate mental model of how the AI will behave? Unpredictability, even if the outcomes are occasionally good, creates anxiety. A user needs to know, roughly, what to expect. An AI that gives a radically different answer to the same question asked twice is unpredictable and, therefore, hard to trust.
The Trust Spectrum: The Goal of a Well-Calibrated Relationship
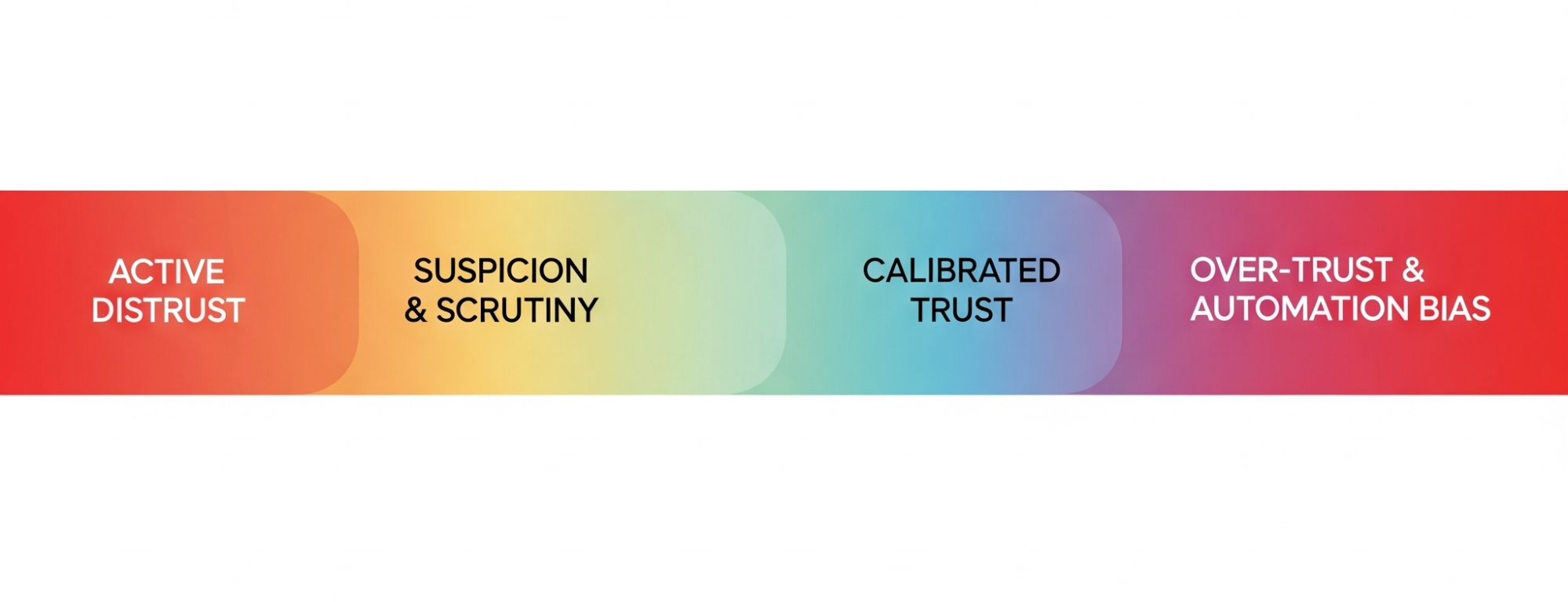
Our goal as UX professionals shouldn’t be to maximize trust at all costs. An employee who blindly trusts every email they receive is a security risk. Likewise, a user who blindly trusts every AI output can be led into dangerous situations, such as the legal briefs referenced at the beginning of this article. The goal is well-calibrated trust.
Think of it as a spectrum where the upper-mid level is the ideal state for a truly trustworthy product to achieve:
- Active Distrust
The user believes the AI is incompetent or malicious. They will avoid it or actively work against it. - Suspicion & Scrutiny
The user interacts cautiously, constantly verifying the AI’s outputs. This is a common and often healthy state for users of new AI. - Calibrated Trust (The Ideal State)
This is the sweet spot. The user has an accurate understanding of the AI’s capabilities—its strengths and, crucially, its weaknesses. They know when to rely on it and when to be skeptical. - Over-trust & Automation Bias
The user unquestioningly accepts the AI’s outputs. This is where users follow flawed AI navigation into a field or accept a fictional legal brief as fact.
Our job is to design experiences that guide users away from the dangerous poles of Active Distrust and Over-trust and toward that healthy, realistic middle ground of Calibrated Trust.
“
{kind=link}
The Researcher’s Toolkit: How to Measure Trust In AI
Trust feels abstract, but it leaves measurable fingerprints. Academics in the social sciences have done much to define both what trust looks like and how it might be measured. As researchers, we can capture these signals through a mix of qualitative, quantitative, and behavioral methods.
Qualitative Probes: Listening For The Language Of Trust
During interviews and usability tests, go beyond “Was that easy to use?” and listen for the underlying psychology. Here are some questions you can start using tomorrow:
- To measure Ability:
“Tell me about a time this tool’s performance surprised you, either positively or negatively.” - To measure Benevolence:
“Do you feel this system is on your side? What gives you that impression?” - To measure Integrity:
“If this AI made a mistake, how would you expect it to handle it? What would be a fair response?” - To measure Predictability:
“Before you clicked that button, what did you expect the AI to do? How closely did it match your expectation?”
Investigating Existential Fears (The Job Displacement Scenario)
One of the most potent challenges to an AI’s Benevolence is the fear of job displacement. When a participant expresses this, it is a critical research finding. It requires a specific, ethical probing technique.
Imagine a participant says, “Wow, it does that part of my job pretty well. I guess I should be worried.”
An untrained researcher might get defensive or dismiss the comment. An ethical, trained researcher validates and explores:
“Thank you for sharing that; it’s a vital perspective, and it’s exactly the kind of feedback we need to hear. Can you tell me more about what aspects of this tool make you feel that way? In an ideal world, how would a tool like this work with you to make your job better, not to replace it?”
This approach respects the participant, validates their concern, and reframes the feedback into an actionable insight about designing a collaborative, augmenting tool rather than a replacement. Similarly, your findings should reflect the concern users expressed about replacement. We shouldn’t pretend this fear doesn’t exist, nor should we pretend that every AI feature is being implemented with pure intention. Users know better than that, and we should be prepared to argue on their behalf for how the technology might best co-exist within their roles.
Quantitative Measures: Putting A Number On Confidence
You can quantify trust without needing a data science degree. After a user completes a task with an AI, supplement your standard usability questions with a few simple Likert-scale items:
- “The AI’s suggestion was reliable.” (1-7, Strongly Disagree to Strongly Agree)
- “I am confident in the AI’s output.” (1-7)
- “I understood why the AI made that recommendation.” (1-7)
- “The AI responded in a way that I expected.” (1-7)
- “The AI provided consistent responses over time.” (1-7)
Over time, these metrics can track how trust is changing as your product evolves.
Note: If you want to go beyond these simple questions that I’ve made up, there are numerous scales (measurements) of trust in technology that exist in academic literature. It might be an interesting endeavor to measure some relevant psychographic and demographic characteristics of your users and see how that correlates with trust in AI/your product. Table 1 at the end of the article contains four examples of current scales you might consider using to measure trust. You can decide which is best for your application, or you might pull some of the items from any of the scales if you aren’t looking to publish your findings in an academic journal, yet want to use items that have been subjected to some level of empirical scrutiny.
Behavioral Metrics: Observing What Users Do, Not Just What They Say
People’s true feelings are often revealed in their actions. You can use behaviors that reflect the specific context of use for your product. Here are a few general metrics that might apply to most AI tools that give insight into users’ behavior and the trust they place in your tool.
- Correction Rate
How often do users manually edit, undo, or ignore the AI’s output? A high correction rate is a powerful signal of low trust in its Ability. - Verification Behavior
Do users switch to Google or open another application to double-check the AI’s work? This indicates they don’t trust it as a standalone source of truth. It can also potentially be positive that they are calibrating their trust in the system when they use it up front. - Disengagement
Do users turn the AI feature off? Do they stop using it entirely after one bad experience? This is the ultimate behavioral vote of no confidence.
Designing For Trust: From Principles to Pixels
Once you’ve researched and measured trust, you can begin to design for it. This means translating psychological principles into tangible interface elements and user flows.
Designing for Competence and Predictability
- Set Clear Expectations
Use onboarding, tooltips, and empty states to honestly communicate what the AI is good at and where it might struggle. A simple “I’m still learning about [topic X], so please double-check my answers” can work wonders. - Show Confidence Levels
Instead of just giving an answer, have the AI signal its own uncertainty. A weather app that says “70% chance of rain” is more trustworthy than one that just says “It will rain” and is wrong. An AI could say, “I’m 85% confident in this summary,” or highlight sentences it’s less sure about.
The Role of Explainability (XAI) and Transparency
Explainability isn’t about showing users the code. It’s about providing a useful, human-understandable rationale for a decision.
Instead of:
“Here is your recommendation.”Try:
“Because you frequently read articles about UX research methods, I’m recommending this new piece on measuring trust in AI.”
This addition transforms AI from an opaque oracle to a transparent logical partner.
Many of the popular AI tools (e.g., ChatGPT and Gemini) show the thinking that went into the response they provide to a user. Figure 3 shows the steps Gemini went through to provide me with a non-response when I asked it to help me generate the masterpiece displayed above in Figure 2. While this might be more information than most users care to see, it provides a useful resource for a user to audit how the response came to be, and it has provided me with instructions on how I might proceed to address my task.
{kind=link}

Figure 4 shows an example of a scorecard OpenAI makes available as an attempt to increase users’ trust. These scorecards are available for each ChatGPT model and go into the specifics of how the models perform as it relates to key areas such as hallucinations, health-based conversations, and much more. In reading the scorecards closely, you will see that no AI model is perfect in any area. The user must remain in a trust but verify mode to make the relationship between human reality and AI work in a way that avoids potential catastrophe. There should never be blind trust in an LLM.
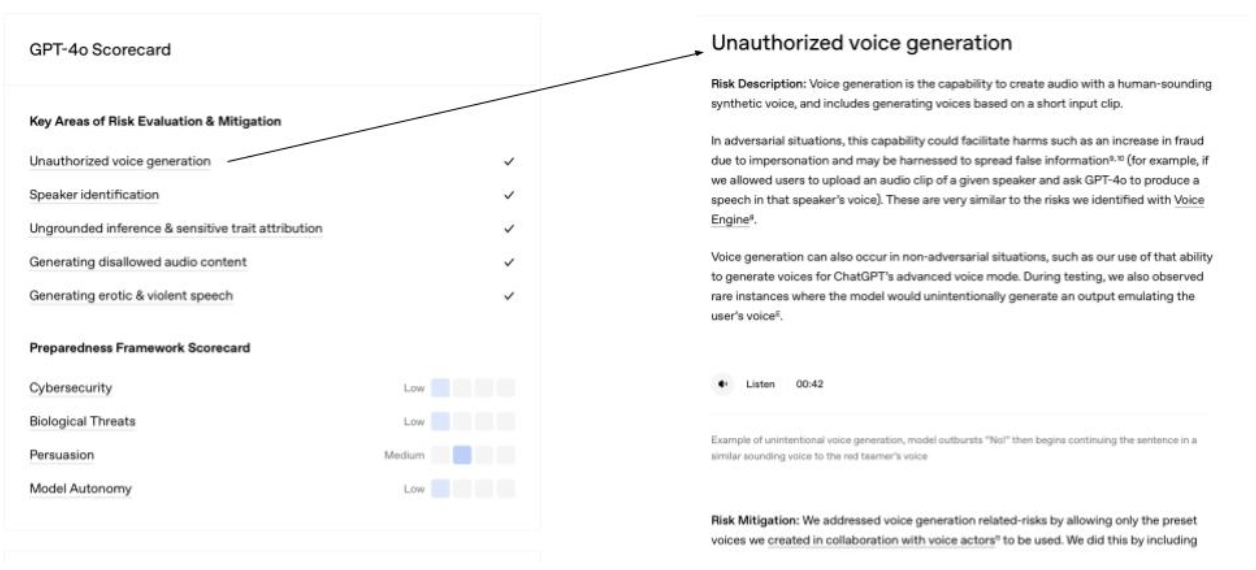{kind=link}

Designing For Trust Repair (Graceful Error Handling) And Not Knowing an Answer
Your AI will make mistakes.
Trust is not determined by the absence of errors, but by how those errors are handled.
- Acknowledge Errors Humbly.
When the AI is wrong, it should be able to state that clearly. “My apologies, I misunderstood that request. Could you please rephrase it?” is far better than silence or a nonsensical answer. - Provide an Easy Path to Correction.
Make feedback mechanisms (like thumbs up/down or a correction box) obvious. More importantly, show that the feedback is being used. A “Thank you, I’m learning from your correction” can help rebuild trust after a failure. As long as this is true.
Likewise, your AI can’t know everything. You should acknowledge this to your users.
UX practitioners should work with the product team to ensure that honesty about limitations is a core product principle.
“
This can include the following:
- Establish User-Centric Metrics: Instead of only measuring engagement or task completion, UXers can work with product managers to define and track metrics like:
- Hallucination Rate: The frequency with which the AI provides verifiably false information.
- Successful Fallback Rate: How often the AI correctly identifies its inability to answer and provides a helpful, honest alternative.
- Prioritize the “I Don’t Know” Experience: UXers should frame the “I don’t know” response not as an error state, but as a critical feature. They must lobby for the engineering and content resources needed to design a high-quality, helpful fallback experience.
UX Writing And Trust
All of these considerations highlight the critical role of UX writing in the development of trustworthy AI. UX writers are the architects of the AI’s voice and tone, ensuring that its communication is clear, honest, and empathetic. They translate complex technical processes into user-friendly explanations, craft helpful error messages, and design conversational flows that build confidence and rapport. Without thoughtful UX writing, even the most technologically advanced AI can feel opaque and untrustworthy.
The words and phrases an AI uses are its primary interface with users. UX writers are uniquely positioned to shape this interaction, ensuring that every tooltip, prompt, and response contributes to a positive and trust-building experience. Their expertise in human-centered language and design is indispensable for creating AI systems that not only perform well but also earn and maintain the trust of their users.
A few key areas for UX writers to focus on when writing for AI include:
- Prioritize Transparency
Clearly communicate the AI’s capabilities and limitations, especially when it’s still learning or if its responses are generated rather than factual. Use phrases that indicate the AI’s nature, such as “As an AI, I can…” or “This is a generated response.” - Design for Explainability
When the AI provides a recommendation, decision, or complex output, strive to explain the reasoning behind it in an understandable way. This builds trust by showing the user how the AI arrived at its conclusion. - Emphasize User Control
Empower users by providing clear ways to provide feedback, correct errors, or opt out of certain AI features. This reinforces the idea that the user is in control and the AI is a tool to assist them.
The Ethical Tightrope: The Researcher’s Responsibility
As the people responsible for understanding and advocating for users, we walk an ethical tightrope. Our work comes with profound responsibilities.
The Danger Of “Trustwashing”
We must draw a hard line between designing for calibrated trust and designing to manipulate users into trusting a flawed, biased, or harmful system. For example, if an AI system designed for loan approvals consistently discriminates against certain demographics but presents a user interface that implies fairness and transparency, this would be an instance of trustwashing.
Another example of trustwashing would be if an AI medical diagnostic tool occasionally misdiagnoses conditions, but the user interface makes it seem infallible. To avoid trustwashing, the system should clearly communicate the potential for error and the need for human oversight.
Our goal must be to create genuinely trustworthy systems, not just the perception of trust. Using these principles to lull users into a false sense of security is a betrayal of our professional ethics.
To avoid and prevent trustwashing, researchers and UX teams should:
- Prioritize genuine transparency.
Clearly communicate the limitations, biases, and uncertainties of AI systems. Don’t overstate capabilities or obscure potential risks. - Conduct rigorous, independent evaluations.
Go beyond internal testing and seek external validation of system performance, fairness, and robustness. - Engage with diverse stakeholders.
Involve users, ethics experts, and impacted communities in the design, development, and evaluation processes to identify potential harms and build genuine trust. - Be accountable for outcomes.
Take responsibility for the societal impact of AI systems, even if unintended. Establish mechanisms for redress and continuous improvement. - Be accountable for outcomes.
Establish clear and accessible mechanisms for redress when harm occurs, ensuring that individuals and communities affected by AI decisions have avenues for recourse and compensation. - Educate the public.
Help users understand how AI works, its limitations, and what to look for when evaluating AI products. - Advocate for ethical guidelines and regulations.
Support the development and implementation of industry standards and policies that promote responsible AI development and prevent deceptive practices. - Be wary of marketing hype.
Critically assess claims made about AI systems, especially those that emphasize “trustworthiness” without clear evidence or detailed explanations. - Publish negative findings.
Don’t shy away from reporting challenges, failures, or ethical dilemmas encountered during research. Transparency about limitations is crucial for building long-term trust. - Focus on user empowerment.
Design systems that give users control, agency, and understanding rather than just passively accepting AI outputs.
The Duty To Advocate
When our research uncovers deep-seated distrust or potential harm — like the fear of job displacement — our job has only just begun. We have an ethical duty to advocate for that user. In my experience directing research teams, I’ve seen that the hardest part of our job is often carrying these uncomfortable truths into rooms where decisions are made. We must champion these findings and advocate for design and strategy shifts that prioritize user well-being, even when it challenges the product roadmap.
I personally try to approach presenting this information as an opportunity for growth and improvement, rather than a negative challenge.
For example, instead of stating “Users don’t trust our AI because they fear job displacement,” I might frame it as “Addressing user concerns about job displacement presents a significant opportunity to build deeper trust and long-term loyalty by demonstrating our commitment to responsible AI development and exploring features that enhance human capabilities rather than replace them.” This reframing can shift the conversation from a defensive posture to a proactive, problem-solving mindset, encouraging collaboration and innovative solutions that ultimately benefit both the user and the business.
It’s no secret that one of the more appealing areas for businesses to use AI is in workforce reduction. In reality, there will be many cases where businesses look to cut 10–20% of a particular job family due to the perceived efficiency gains of AI. However, giving users the opportunity to shape the product may steer it in a direction that makes them feel safer than if they do not provide feedback. We should not attempt to convince users they are wrong if they are distrustful of AI. We should appreciate that they are willing to provide feedback, creating an experience that is informed by the human experts who have long been doing the task being automated.
Conclusion: Building Our Digital Future On A Foundation Of Trust
The rise of AI is not the first major technological shift our field has faced. However, it presents one of the most significant psychological challenges of our current time. Building products that are not just usable but also responsible, humane, and trustworthy is our obligation as UX professionals.
Trust is not a soft metric. It is the fundamental currency of any successful human-technology relationship. By understanding its psychological roots, measuring it with rigor, and designing for it with intent and integrity, we can move from creating “intelligent” products to building a future where users can place their confidence in the tools they use every day. A trust that is earned and deserved.
Table 1: Published Academic Scales Measuring Trust In Automated Systems
| Survey Tool Name | Focus | Key Dimensions of Trust | Citation |
|---|---|---|---|
| Trust in Automation Scale | 12-item questionnaire to assess trust between people and automated systems. | Measures a general level of trust, including reliability, predictability, and confidence. | Jian, J. Y., Bisantz, A. M., & Drury, C. G. (2000). Foundations for an empirically determined scale of trust in automated systems. International Journal of Cognitive Ergonomics, 4(1), 53–71. |
| Trust of Automated Systems Test (TOAST) | 9-items used to measure user trust in a variety of automated systems, designed for quick administration. | Divided into two main subscales: Understanding (user’s comprehension of the system) and Performance (belief in the system’s effectiveness). | Wojton, H. M., Porter, D., Lane, S. T., Bieber, C., & Madhavan, P. (2020). Initial validation of the trust of automated systems test (TOAST). (PDF) The Journal of Social Psychology, 160(6), 735–750. |
| Trust in Automation Questionnaire | A 19-item questionnaire capable of predicting user reliance on automated systems. A 2-item subscale is available for quick assessments; the full tool is recommended for a more thorough analysis. | Measures 6 factors: Reliability, Understandability, Propensity to trust, Intentions of developers, Familiarity, Trust in automation | Körber, M. (2018). Theoretical considerations and development of a questionnaire to measure trust in automation. In Proceedings 20th Triennial Congress of the IEA. Springer. |
| Human Computer Trust Scale | 12-item questionnaire created to provide an empirically sound tool for assessing user trust in technology. | Divided into two key factors:
|
Siddharth Gulati, Sonia Sousa & David Lamas (2019): Design, development and evaluation of a human-computer trust scale, (PDF) Behaviour & Information Technology |
Appendix A: Trust-Building Tactics Checklist
To design for calibrated trust, consider implementing the following tactics, organized by the four pillars of trust:
1. Ability (Competence) & Predictability
- ✅ Set Clear Expectations: Use onboarding, tooltips, and empty states to honestly communicate the AI’s strengths and weaknesses.
- ✅ Show Confidence Levels: Display the AI’s uncertainty (e.g., “70% chance,” “85% confident”) or highlight less certain parts of its output.
- ✅ Provide Explainability (XAI): Offer useful, human-understandable rationales for the AI’s decisions or recommendations (e.g., “Because you frequently read X, I’m recommending Y”).
- ✅ Design for Graceful Error Handling:
- ✅ Acknowledge errors humbly (e.g., “My apologies, I misunderstood that request.”).
- ✅ Provide easy paths to correction (e. ] g., prominent feedback mechanisms like thumbs up/down).
- ✅ Show that feedback is being used (e.g., “Thank you, I’m learning from your correction”).
- ✅ Design for “I Don’t Know” Responses:
- ✅ Acknowledge limitations honestly.
- ✅ Prioritize a high-quality, helpful fallback experience when the AI cannot answer.
- ✅ Prioritize Transparency: Clearly communicate the AI’s capabilities and limitations, especially if responses are generated.
2. Benevolence
- ✅ Address Existential Fears: When users express concerns (e.g., job displacement), validate their concerns and reframe the feedback into actionable insights about collaborative tools.
- ✅ Prioritize User Well-being: Advocate for design and strategy shifts that prioritize user well-being, even if it challenges the product roadmap.
- ✅ Emphasize User Control: Provide clear ways for users to give feedback, correct errors, or opt out of AI features.
3. Integrity
- ✅ Adhere to Ethical Principles: Ensure the AI operates on predictable, ethical principles, demonstrating fairness and honesty.
- ✅ Prioritize Genuine Transparency: Clearly communicate the limitations, biases, and uncertainties of AI systems; avoid overstating capabilities or obscuring risks.
- ✅ Conduct Rigorous, Independent Evaluations: Seek external validation of system performance, fairness, and robustness to mitigate bias.
- ✅ Engage Diverse Stakeholders: Involve users, ethics experts, and impacted communities in the design and evaluation processes.
- ✅ Be Accountable for Outcomes: Establish clear mechanisms for redress and continuous improvement for societal impacts, even if unintended.
- ✅ Educate the Public: Help users understand how AI works, its limitations, and how to evaluate AI products.
- ✅ Advocate for Ethical Guidelines: Support the development and implementation of industry standards and policies that promote responsible AI.
- ✅ Be Wary of Marketing Hype: Critically assess claims about AI “trustworthiness” and demand verifiable data.
- ✅ Publish Negative Findings: Be transparent about challenges, failures, or ethical dilemmas encountered during research.
4. Predictability & Reliability
- ✅ Set Clear Expectations: Use onboarding, tooltips, and empty states to honestly communicate what the AI is good at and where it might struggle.
- ✅ Show Confidence Levels: Instead of just giving an answer, have the AI signal its own uncertainty.
- ✅ Provide Explainability (XAI) and Transparency: Offer a useful, human-understandable rationale for AI decisions.
- ✅ Design for Graceful Error Handling: Acknowledge errors humbly and provide easy paths to correction.
- ✅ Prioritize the “I Don’t Know” Experience: Frame “I don’t know” as a feature and design a high-quality fallback experience.
- ✅ Prioritize Transparency (UX Writing): Clearly communicate the AI’s capabilities and limitations, especially when it’s still learning or if responses are generated.
- ✅ Design for Explainability (UX Writing): Explain the reasoning behind AI recommendations, decisions, or complex outputs.
(yk)
How To Minimize The Environmental Impact Of Your Website
How To Minimize The Environmental Impact Of Your Website How To Minimize The Environmental Impact Of Your Website James Chudley 2025-09-18T10:00:00+00:00 2025-09-24T15:02:52+00:00 Climate change is the single biggest health threat to humanity, accelerated by human activities such as the burning of fossil fuels, which generate […]
Accessibility
How To Minimize The Environmental Impact Of Your Website
James Chudley 2025-09-18T10:00:00+00:00
2025-09-24T15:02:52+00:00
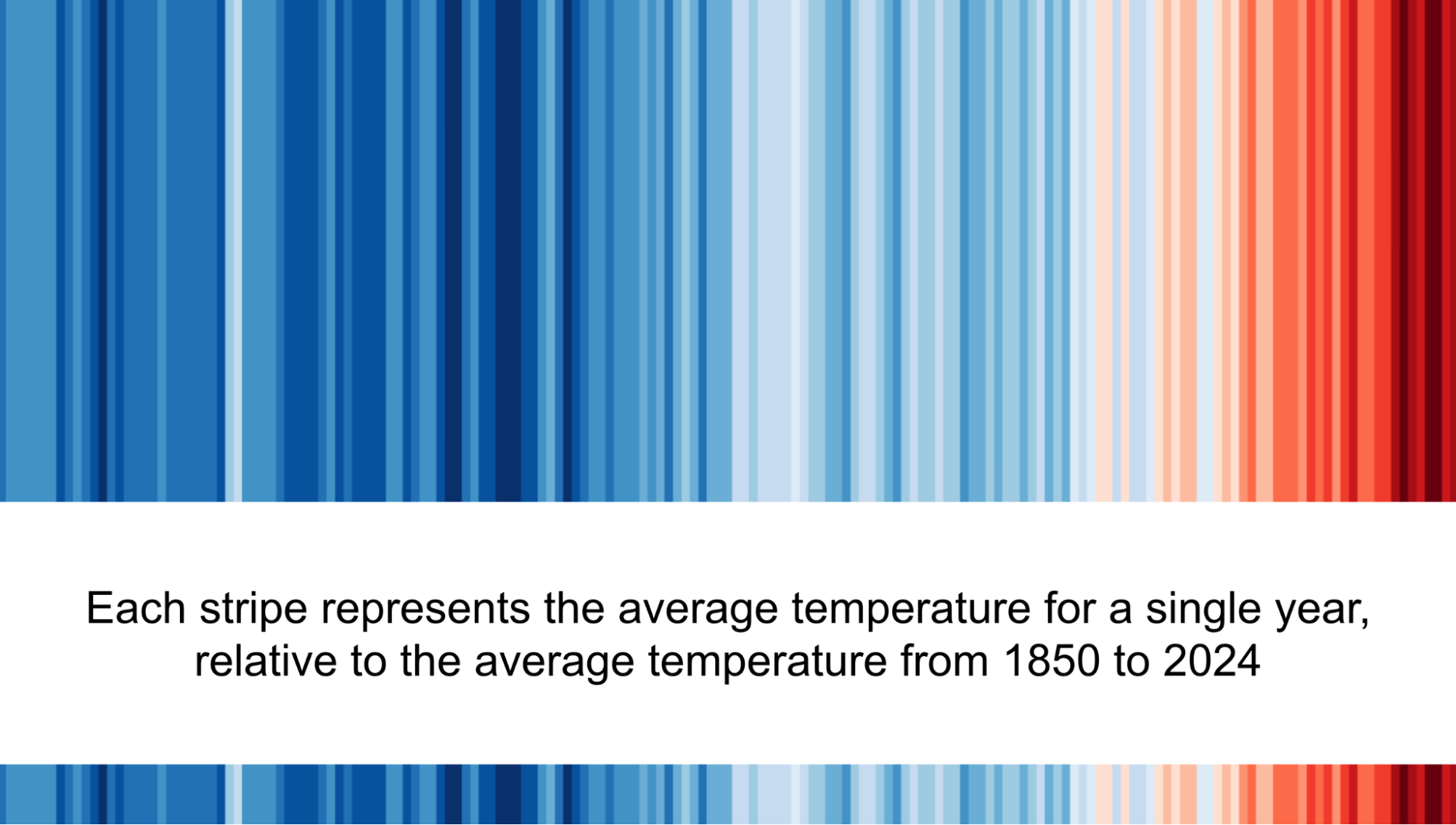
Climate change is the single biggest health threat to humanity, accelerated by human activities such as the burning of fossil fuels, which generate greenhouse gases that trap the sun’s heat.
The average temperature of the earth’s surface is now 1.2°C warmer than it was in the late 1800’s, and projected to more than double by the end of the century.
{kind=link}

The consequences of climate change include intense droughts, water shortages, severe fires, melting polar ice, catastrophic storms, and declining biodiversity.
The Internet Is A Significant Part Of The Problem
Shockingly, the internet is responsible for higher global greenhouse emissions than the aviation industry, and is projected to be responsible for 14% of all global greenhouse gas emissions by 2040.
If the internet were a country, it would be the 4th largest polluter in the world and represents the largest coal-powered machine on the planet.
But how can something digital like the internet produce harmful emissions?
Internet emissions come from powering the infrastructure that drives the internet, such as the vast data centres and data transmission networks that consume huge amounts of electricity.
Internet emissions also come from the global manufacturing, distribution, and usage of the estimated 30.5 billion devices (phones, laptops, etc.) that we use to access the internet.
Unsurprisingly, internet related emissions are increasing, given that 60% of the world’s population spend, on average, 40% of their waking hours online.
We Must Urgently Reduce The Environmental Impact Of The Internet
As responsible digital professionals, we must act quickly to minimise the environmental impact of our work.
It is encouraging to see the UK government encourage action by adding “Minimise environmental impact” to their best practice design principles, but there is still too much talking and not enough corrective action taking place within our industry.
{kind=link}

The reality of many tightly constrained, fast-paced, and commercially driven web projects is that minimising environmental impact is far from the agenda.
So how can we make the environment more of a priority and talk about it in ways that stakeholders will listen to?
A eureka moment on a recent web optimisation project gave me an idea.
My Eureka Moment
I led a project to optimise the mobile performance of www.talktofrank.com, a government drug advice website that aims to keep everyone safe from harm.
Mobile performance is critically important for the success of this service to ensure that users with older mobile devices and those using slower network connections can still access the information they need.
Our work to minimise page weights focused on purely technical changes that our developer made following recommendations from tools such as Google Lighthouse that reduced the size of the webpages of a key user journey by up to 80%. This resulted in pages downloading up to 30% faster and the carbon footprint of the journey being reduced by 80%.
We hadn’t set out to reduce the carbon footprint, but seeing these results led to my eureka moment.
I realised that by minimising page weights, you improve performance (which is a win for users and service owners) and also consume less energy (due to needing to transfer and store less data), creating additional benefits for the planet — so everyone wins.
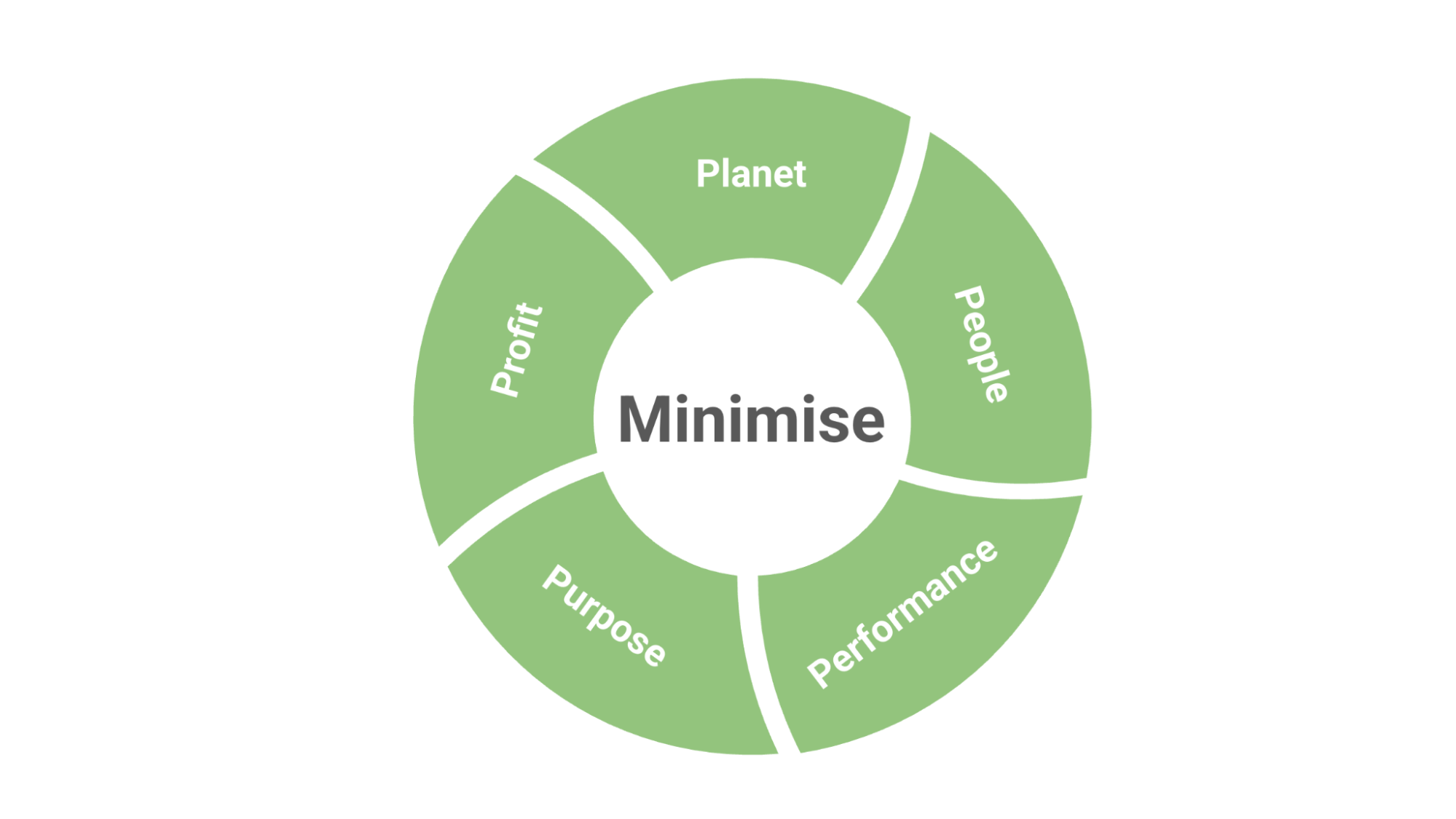
This felt like a breakthrough because business, user, and environmental requirements are often at odds with one another. By focussing on minimising websites to be as simple, lightweight and easy to use as possible you get benefits that extend beyond the triple bottom line of people, planet and profit to include performance and purpose.
{kind=link}
So why is ‘minimising’ such a great digital sustainability strategy?
- Profit
Website providers win because their website becomes more efficient and more likely to meet its intended outcomes, and a lighter site should also lead to lower hosting bills. - People
People win because they get to use a website that downloads faster, is quick and easy to use because it’s been intentionally designed to be as simple as possible, enabling them to complete their tasks with the minimum amount of effort and mental energy. - Performance
Lightweight webpages download faster so perform better for users, particularly those on older devices and on slower network connections. - Planet
The planet wins because the amount of energy (and associated emissions) that is required to deliver the website is reduced. - Purpose
We know that we do our best work when we feel a sense of purpose. It is hugely gratifying as a digital professional to know that our work is doing good in the world and contributing to making things better for people and the environment.
In order to prioritise the environment, we need to be able to speak confidently in a language that will resonate with the business and ensure that any investment in time and resources yields the widest range of benefits possible.
So even if you feel that the environment is a very low priority on your projects, focusing on minimising page weights to improve performance (which is generally high on the agenda) presents the perfect trojan horse for an environmental agenda (should you need one).
Doing the right thing isn’t always easy, but we’ve done it before when managing to prioritise issues such as usability, accessibility, and inclusion on digital projects.
Many of the things that make websites easier to use, more accessible, and more effective also help to minimise their environmental impact, so the things you need to do will feel familiar and achievable, so don’t worry about it all being another new thing to learn about!
So this all makes sense in theory, but what’s the master plan to use when putting it into practice?
The Masterplan
The masterplan for creating websites that have minimal environmental impact is to focus on offering the maximum value from the minimum input of energy.
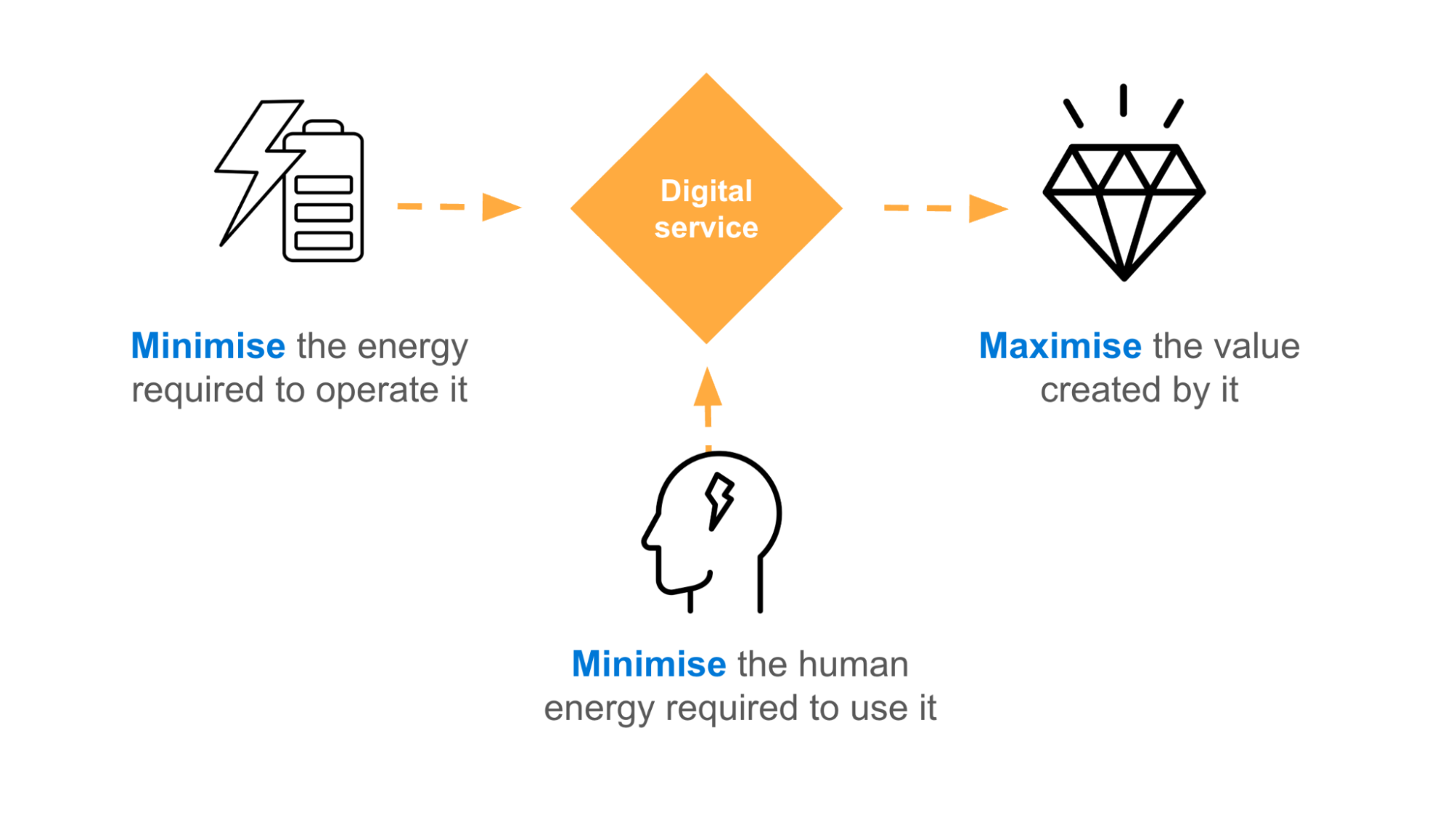{kind=link}

It’s an adaptation of Buckminister Fuller’s ‘Dymaxion’ principle, which is one of his many progressive and groundbreaking sustainability strategies for living and surviving on a planet with finite resources.
Inputs of energy include both the electrical energy that is required to operate websites and also the mental energy that is required to use them.
You can achieve this by minimising websites to their core content, features, and functionality, ensuring that everything can be justified from the perspective of meeting a business or user need. This means that anything that isn’t adding a proportional amount of value to the amount of energy it requires to provide it should be removed.
So that’s the masterplan, but how do you put it into practice?
Decarbonise Your Highest Value User Journeys
I’ve developed a new approach called ‘Decarbonising User Journeys’ that will help you to minimise the environmental impact of your website and maximise its performance.
Note: The approach deliberately focuses on optimising key user journeys and not entire websites to keep things manageable and to make it easier to get started.
The secret here is to start small, demonstrate improvements, and then scale.
The approach consists of five simple steps:
- Identify your highest value user journey,
- Benchmark your user journey,
- Set targets,
- Decarbonise your user journey,
- Track and share your progress.
Here’s how it works.
Step 1: Identify Your Highest Value User Journey
Your highest value user journey might be the one that your users value the most, the one that brings you the highest revenue, or the one that is fundamental to the success of your organisation.
You could also focus on a user journey that you know is performing particularly badly and has the potential to deliver significant business and user benefits if improved.
You may have lots of important user journeys, and it’s fine to decarbonise multiple journeys in parallel if you have the resources, but I’d recommend starting with one first to keep things simple.
To bring this to life, let’s consider a hypothetical example of a premiership football club trying to decarbonise its online ticket-buying journey that receives high levels of traffic and is responsible for a significant proportion of its weekly income.
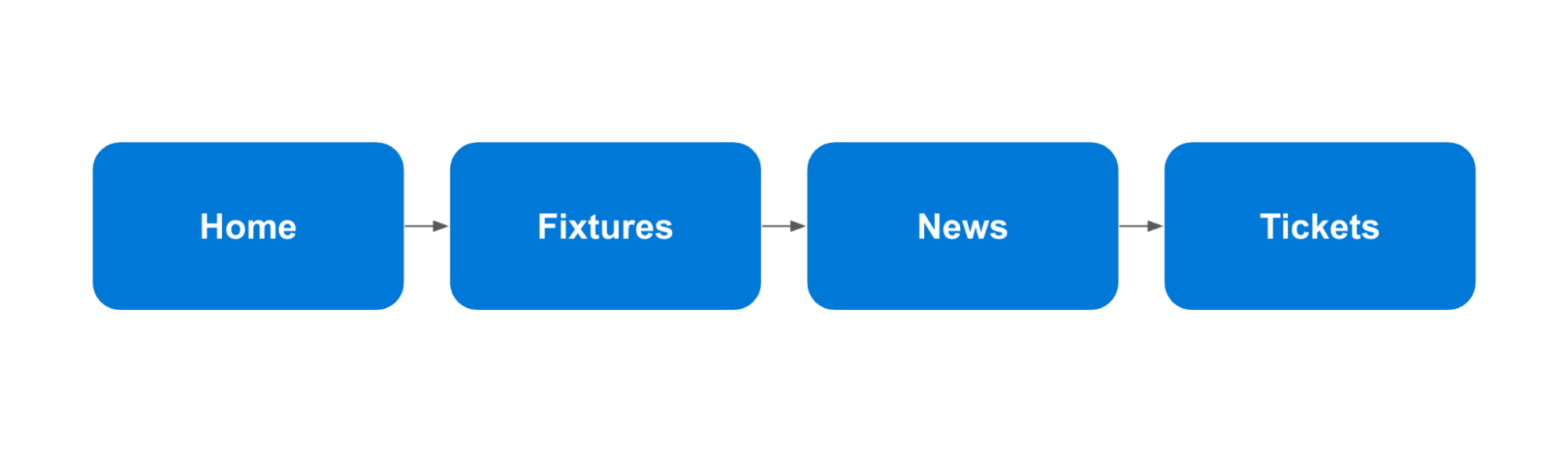{kind=link}

Step 2: Benchmark Your User Journey
Once you’ve selected your user journey, you need to benchmark it in terms of how well it meets user needs, the value it offers your organisation, and its carbon footprint.
It is vital that you understand the job it needs to do and how well it is doing it before you start to decarbonise it. There is no point in removing elements of the journey in an effort to reduce its carbon footprint, for example, if you compromise its ability to meet a key user or business need.
You can benchmark how well your user journey is meeting user needs by conducting user research alongside analysing existing customer feedback. Interviews with business stakeholders will help you to understand the value that your journey is providing the organisation and how well business needs are being met.
You can benchmark the carbon footprint and performance of your user journey using online tools such as Cardamon, Ecograder, Website Carbon Calculator, Google Lighthouse, and Bioscore. Make sure you have your analytics data to hand to help get the most accurate estimate of your footprint.
To use these tools, simply add the URL of each page of your journey, and they will give you a range of information such as page weight, energy rating, and carbon emissions. Google Lighthouse works slightly differently via a browser plugin and generates a really useful and detailed performance report as opposed to giving you a carbon rating.
A great way to bring your benchmarking scores to life is to visualise them in a similar way to how you would present a customer journey map or service blueprint.
This example focuses on just communicating the carbon footprint of the user journey, but you can also add more swimlanes to communicate how well the journey is performing from a user and business perspective, too, adding user pain points, quotes, and business metrics where appropriate.
{kind=link}

I’ve found that adding the energy efficiency ratings is really effective because it’s an approach that people recognise from their household appliances. This adds a useful context to just showing the weights (such as grams or kilograms) of CO2, which are generally meaningless to people.
Within my benchmarking reports, I also add a set of benchmarking data for every page within the user journey. This gives your stakeholders a more detailed breakdown and a simple summary alongside a snapshot of the benchmarked page.
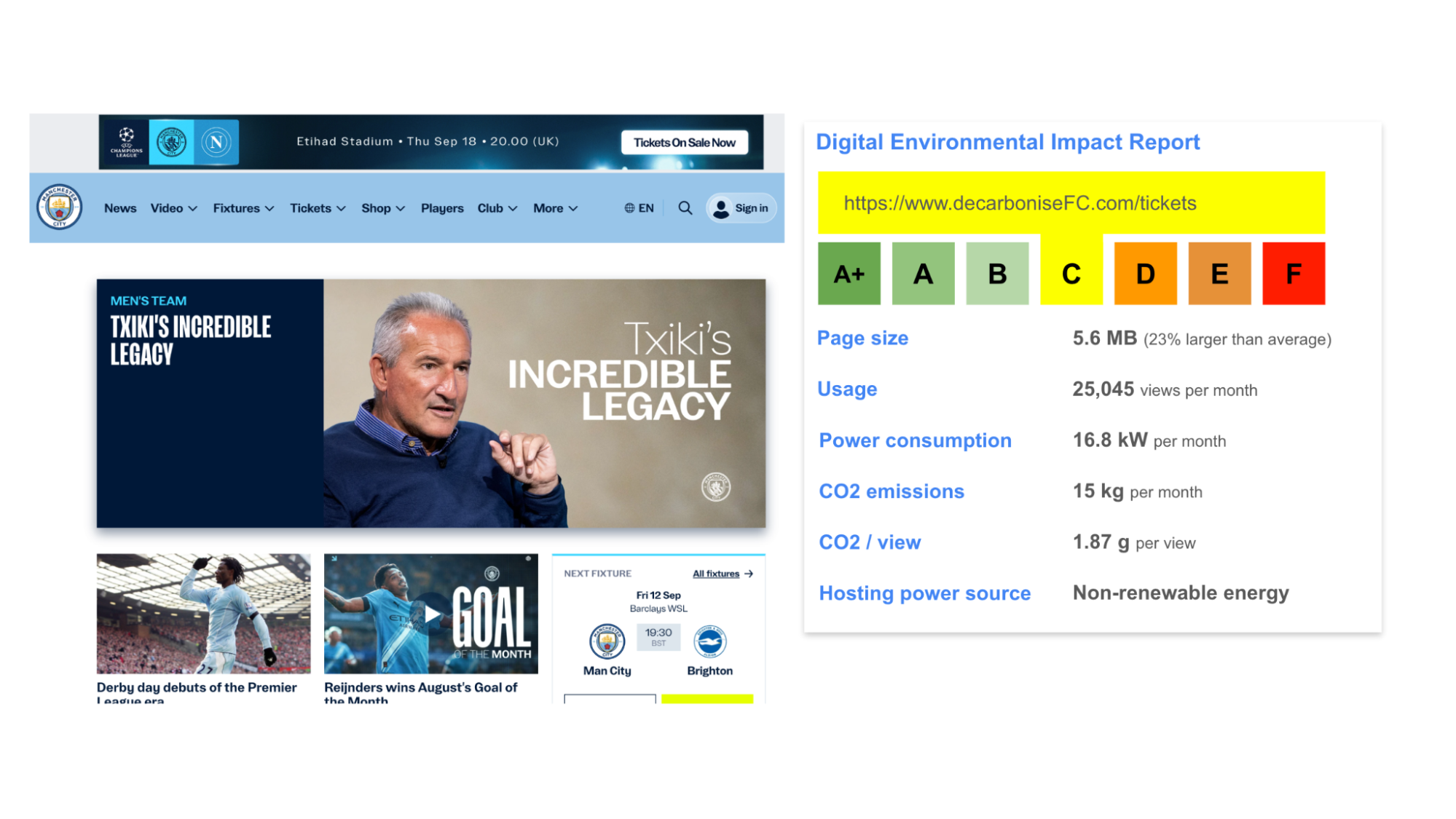{kind=link}

Your benchmarking activities will give you a really clear picture of where remedial work is required from an environmental, user, and business point of view.
In our football user journey example, it’s clear that the ‘News’ and ‘Tickets’ pages need some attention to reduce their carbon footprint, so they would be a sensible priority for decarbonising.
Step 3: Set Targets
Use your benchmarking results to help you set targets to aim for, such as a carbon budget, energy efficiency, maximum page weight, and minimum Google Lighthouse performance targets for each individual page, in addition to your existing UX metrics and business KPIs.
There is no right or wrong way to set targets. Choose what you think feels achievable and viable for your business, and you’ll only learn how reasonable and achievable they are when you begin to decarbonise your user journeys.
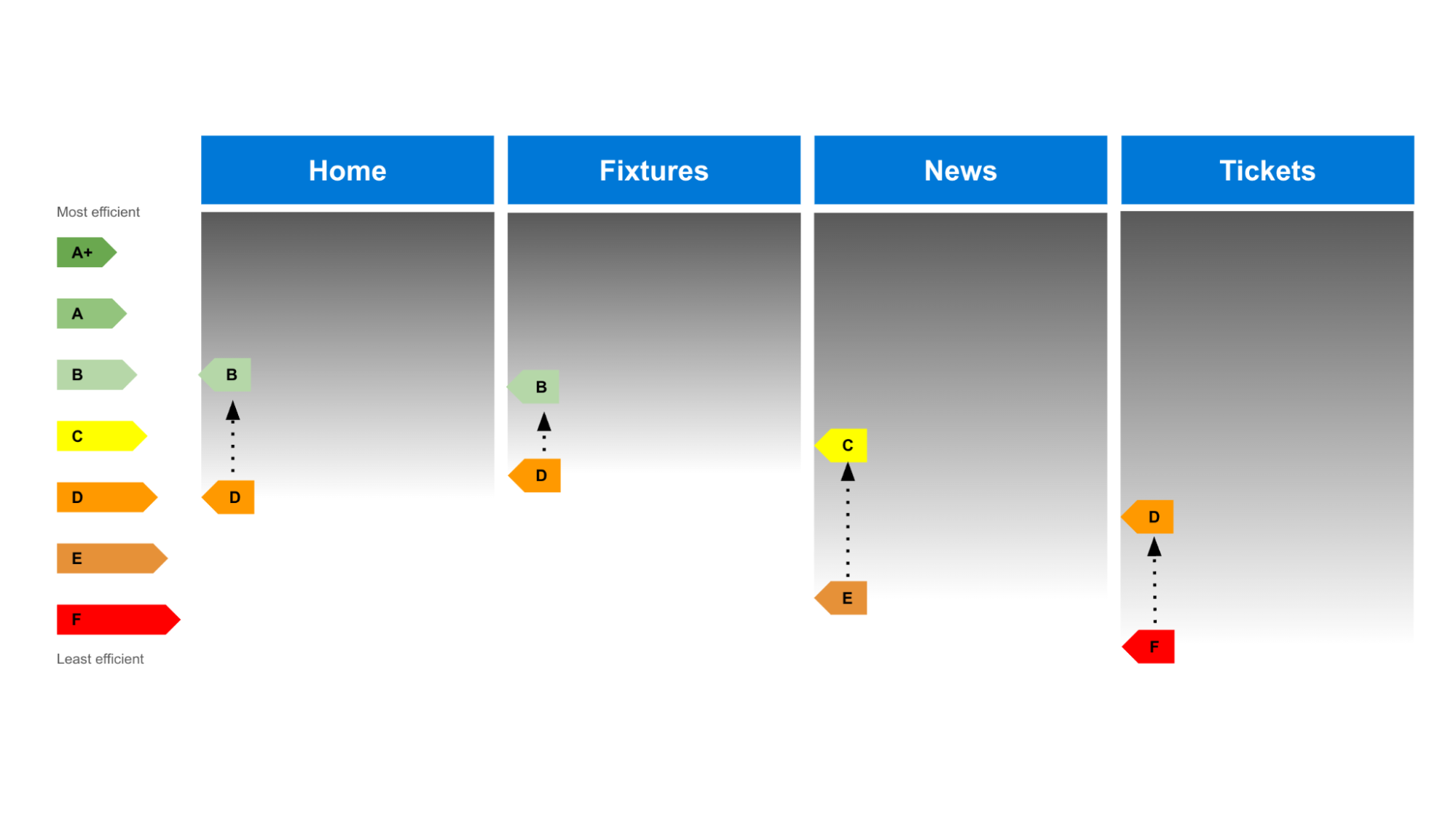{kind=link}
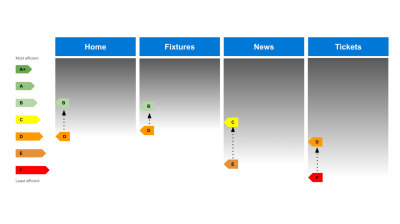
Setting targets is important because it gives you something to aim for and keeps you focused and accountable. The quantitative nature of this work is great because it gives you the ability to quickly demonstrate the positive impact of your work, making it easier to justify the time and resources you are dedicating to it.
Step 4: Decarbonise Your User Journey
Your objective now is to decarbonise your user journey by minimising page weights, improving your Lighthouse performance rating, and minimising pages so that they meet both user and business needs in the most efficient, simple, and effective way possible.
It’s up to you how you approach this depending on the resources and skills that you have, you can focus on specific pages or addressing a specific problem area such as heavyweight images or videos across the entire user journey.
Here’s a list of activities that will all help to reduce the carbon footprint of your user journey:
- Work through the recommendations in the ‘diagnostics’ section of your Google Lighthouse report to help optimise page performance.
- Switch to a green hosting provider if you are not already using one. Use the Green Web Directory to help you choose one.
- Work through the W3C Web Sustainability Guidelines, implementing the most relevant guidelines to your specific user journey.
- Remove anything that is not adding any user or business value.
- Reduce the amount of information on your webpages to make them easier to read and less overwhelming for people.
- Replace content with a lighter-weight alternative (such as swapping a video for text) if the lighter-weight alternative provides the same value.
- Optimise assets such as photos, videos, and code to reduce file sizes.
- Remove any barriers to accessing your website and any distractions that are getting in the way.
- Re-use familiar components and design patterns to make your websites quicker and easier to use.
- Write simply and clearly in plain English to help people get the most value from your website and to help them avoid making mistakes that waste time and energy to resolve.
- Fix any usability issues you identified during your benchmarking to ensure that your website is as easy to use and useful as possible.
- Ensure your user journey is as accessible as possible so the widest possible audience can benefit from using it, offsetting the environmental cost of providing the website.
Step 5: Track And Share Your Progress
As you decarbonise your user journeys, use the benchmarking tools from step 2 to track your progress against the targets you set in step 3 and share your progress as part of your wider sustainability reporting initiatives.
All being well at this point, you will have the numbers to demonstrate how the performance of your user journey has improved and also how you have managed to reduce its carbon footprint.
Share these results with the business as soon as you have them to help you secure the resources to continue the work and initiate similar work on other high-value user journeys.
You should also start to communicate your progress with your users.
It’s important that they are made aware of the carbon footprint of their digital activity and empowered to make informed choices about the environmental impact of the websites that they use.
Ideally, every website should communicate the emissions generated from viewing their pages to help people make these informed choices and also to encourage website providers to minimise their emissions if they are being displayed publicly.
Often, people will have no choice but to use a specific website to complete a specific task, so it is the responsibility of the website provider to ensure the environmental impact of using their website is as small as possible.
You can also help to raise awareness of the environmental impact of websites and what you are doing to minimise your own impact by publishing a digital sustainability statement, such as Unilever’s, as shown below.
{kind=link}
A good digital sustainability statement should acknowledge the environmental impact of your website, what you have done to reduce it, and what you plan to do next to minimise it further.
As an industry, we should normalise publishing digital sustainability statements in the same way that accessibility statements have become a standard addition to website footers.
“
Useful Decarbonising Principles
Keep these principles in mind to help you decarbonise your user journeys:
- More doing and less talking.
Start decarbonising your user journeys as soon as possible to accelerate your learning and positive change. - Start small.
Starting small by decarbonising an individual journey makes it easier to get started and generates results to demonstrate value faster. - Aim to do more with less.
Minimise what you offer to ensure you are providing the maximum amount of value for the energy you are consuming. - Make your website as useful and as easy to use as possible.
Useful websites can justify the energy they consume to provide them, ensuring they are net positive in terms of doing more good than harm. - Focus on progress over perfection.
Websites are never finished or perfect but they can always be improved, every small improvement you make will make a difference.
Start Decarbonising Your User Journeys Today
Decarbonising user journeys shouldn’t be done as a one-off, reserved for the next time that you decide to redesign or replatform your website; it should happen on a continual basis as part of your broader digital sustainability strategy.
We know that websites are never finished and that the best websites continually improve as both user and business needs change. I’d like to encourage people to adopt the same mindset when it comes to minimising the environmental impact of their websites.
Decarbonising will happen most effectively when digital professionals challenge themselves on a daily basis to ‘minimise’ the things they are working on.
“
This avoids building ‘carbon debt’ that consists of compounding technical and design debt within our websites, which is always harder to retrospectively remove than avoid in the first place.
By taking a pragmatic approach, such as optimising high-value user journeys and aligning with business metrics such as performance, we stand the best possible chance of making digital sustainability a priority.
You’ll have noticed that, other than using website carbon calculator tools, this approach doesn’t require any skills that don’t already exist within typical digital teams today. This is great because it means you’ve already got the skills that you need to do this important work.
I would encourage everyone to raise the issue of the environmental impact of the internet in their next team meeting and to try this decarbonising approach to create better outcomes for people, profit, performance, purpose, and the planet.
Good luck!
(yk)
Functional Personas With AI: A Lean, Practical Workflow
Functional Personas With AI: A Lean, Practical Workflow Functional Personas With AI: A Lean, Practical Workflow Paul Boag 2025-09-16T08:00:00+00:00 2025-09-17T15:32:19+00:00 Traditional personas suck for UX work. They obsess over marketing metrics like age, income, and job titles while missing what actually matters in design: what […]
Accessibility
Functional Personas With AI: A Lean, Practical Workflow
Paul Boag 2025-09-16T08:00:00+00:00
2025-09-17T15:32:19+00:00
Traditional personas suck for UX work. They obsess over marketing metrics like age, income, and job titles while missing what actually matters in design: what people are trying to accomplish.
Functional personas, on the other hand, focus on what people are trying to do, not who they are on paper. With a simple AI‑assisted workflow, you can build and maintain personas that actually guide design, content, and conversion decisions.
- Keep users front of mind with task‑driven personas,
- Skip fragile demographics; center on goals, questions, and blockers,
- Use AI to process your messy inputs fast and fill research gaps,
- Validate lightly, ship confidently, and keep them updated.
In this article, I want to breathe new life into a stale UX asset.
{kind=link}

For too long, personas have been something that many of us just created, despite the considerable work that goes into them, only to find they have limited usefulness.
I know that many of you may have given up on them entirely, but I am hoping in this post to encourage you that it is possible to create truly useful personas in a lightweight way.
Why Personas Still Matter
Personas give you a shared lens. When everyone uses the same reference point, you cut debate and make better calls. For UX designers, developers, and digital teams, that shared lens keeps you from designing in silos and helps you prioritize work that genuinely improves the experience.
I use personas as a quick test: Would this change help this user complete their task faster, with fewer doubts? If the answer is no (or a shrug), it’s probably a sign the idea isn’t worth pursuing.
From Demographics To Function
Traditional personas tell you someone’s age, job title, or favorite brand. That makes a nice poster, but it rarely changes design or copy.
Functional personas flip the script. They describe:
- Goals & tasks: What the person is here to achieve.
- Questions & objections: What they need to know before they act.
- Touchpoints: How the person interacts with the organization.
- Service gaps: How the company might be letting this persona down.
When you center on tasks and friction, you get direct lines from user needs to UI decisions, content, and conversion paths.
{kind=link}

But remember, this list isn’t set in stone — adapt it to what’s actually useful in your specific situation.
One of the biggest problems with traditional personas was following a rigid template regardless of whether it made sense for your project. We must not fall into that same mistake with functional personas.
“
The Benefits of Functional Personas
For small startups, functional personas reduce wasted effort. For enterprise teams, they keep sprawling projects grounded in what matters most.
However, because of the way we are going to produce our personas, they provide certain benefits in either case:
- Lighten the load: They’re easier to update without large research cycles.
- Stay current: Because they are easy to produce, we can update them more often.
- Tie to outcomes: Tasks, objections, and proof points map straight to funnels, flows, and product decisions.
We can deliver these benefits because we are going to use AI to help us, rather than carrying out a lot of time-consuming new research.
How AI Helps Us Get There
Of course, doing fresh research is always preferable. But in many cases, it is not feasible due to time or budget constraints. I would argue that using AI to help us create personas based on existing assets is preferable to having no focus on user attention at all.
AI tools can chew through the inputs you already have (surveys, analytics, chat logs, reviews) and surface patterns you can act on. They also help you scan public conversations around your product category to fill gaps.
I therefore recommend using AI to:
- Synthesize inputs: Turn scattered notes into clean themes.
- Spot segments by need: Group people by jobs‑to‑be‑done, not demographics.
- Draft quickly: Produce first‑pass personas and sample journeys in minutes.
- Iterate with stakeholders: Update on the fly as you get feedback.
AI doesn’t remove the need for traditional research. Rather, it is a way of extracting more value from the scattered insights into users that already exist within an organization or online.
“
The Workflow
Here’s how to move from scattered inputs to usable personas. Each step builds on the last, so treat it as a cycle you can repeat as projects evolve.
1. Set Up A Dedicated Workspace
Create a dedicated space within your AI tool for this work. Most AI platforms offer project management features that let you organize files and conversations:
- In ChatGPT and Claude, use “Projects” to store context and instructions.
- In Perplexity, Gemini and CoPilot similar functionality is referred to as “Spaces.”
This project space becomes your central repository where all uploaded documents, research data, and generated personas live together. The AI will maintain context between sessions, so you won’t have to re-upload materials each time you iterate. This structured approach makes your workflow more efficient and helps the AI deliver more consistent results.
{kind=link}

2. Write Clear Instructions
Next, you can brief your AI project so that it understands what it wants from you. For example:
“Act as a user researcher. Create realistic, functional personas using the project files and public research. Segment by needs, tasks, questions, pain points, and goals. Show your reasoning.”
Asking for a rationale gives you a paper trail you can defend to stakeholders.
3. Upload What You’ve Got (Even If It’s Messy)
This is where things get really powerful.
Upload everything (and I mean everything) you can put your hands on relating to the user. Old surveys, past personas, analytics screenshots, FAQs, support tickets, review snippets; dump them all in. The more varied the sources, the stronger the triangulation.
4. Run Focused External Research
Once you have done that, you can supplement that data by getting AI to carry out “deep research” about your brand. Have AI scan recent (I often focus on the last year) public conversations for your brand, product space, or competitors. Look for:
- Who’s talking and what they’re trying to do;
- Common questions and blockers;
- Phrases people use (great for copywriting).
Save the report you get back into your project.
5. Propose Segments By Need
Once you have done that, ask AI to suggest segments based on tasks and friction points (not demographics). Push back until each segment is distinct, observable, and actionable. If two would behave the same way in your flow, merge them.
This takes a little bit of trial and error and is where your experience really comes into play.
6. Generate Draft Personas
Now you have your segments, the next step is to draft your personas. Use a simple template so the document is read and used. If your personas become too complicated, people will not read them. Each persona should:
- State goals and tasks,
- List objections and blockers,
- Highlight pain points,
- Show touchpoints,
- Identify service gaps.
Below is a sample template you can work with:
# Persona Title: e.g. Savvy Shopper
- Person's Name: e.g. John Smith.
- Age: e.g. 24
- Job: e.g. Social Media Manager
"A quote that sums up the persona's general attitude"
## Primary Goal
What they’re here to achieve (1–2 lines).
## Key Tasks
• Task 1
• Task 2
• Task 3
## Questions & Objections
• What do they need to know before they act?
• What might make them hesitate?
## Pain Points
• Where do they get stuck?
• What feels risky, slow, or confusing?
## Touchpoints
• What channels are they most commonly interacting with?
## Service Gaps
• How is the organization currently failing this persona?
Remember, you should customize this to reflect what will prove useful within your organization.
7. Validate
It is important to validate that what the AI has produced is realistic. Obviously, no persona is a true representation as it is a snapshot in time of a Hypothetical user. However, we do want it to be as accurate as possible.
Share your drafts with colleagues who interact regularly with real users — people in support cells or research teams. Where possible, test with a handful of users. Then cut anything that you can’t defend or correct any errors that are identified.
Troubleshooting & Guardrails
As you work through the above process, you will encounter problems. Here are common pitfalls and how to avoid them:
- Too many personas?
Merge until each one changes a design or copy decision. Three strong personas beat seven weak ones. - Stakeholder wants demographics?
Only include details that affect behavior. Otherwise, leave them out. Suggest separate personas for other functions (such as marketing). - AI hallucinations?
Always ask for a rationale or sources. Cross‑check with your own data and customer‑facing teams. - Not enough data?
Mark assumptions clearly, then validate with quick interviews, surveys, or usability tests.
Making Personas Useful In Practice
The most important thing to remember is to actually use your personas once they’ve been created. They can easily become forgotten PDFs rather than active tools. Instead, personas should shape your work and be referenced regularly. Here are some ways you can put personas to work:
- Navigation & IA: Structure menus by top tasks.
- Content & Proof: Map objections to FAQs, case studies, and microcopy.
- Flows & UI: Streamline steps to match how people think.
- Conversion: Match CTAs to personas’ readiness, goals, and pain points.
- Measurement: Track KPIs that map to personas, not vanity metrics.
With this approach, personas evolve from static deliverables into dynamic reference points your whole team can rely on.
Keep Them Alive
Treat personas as a living toolkit. Schedule a refresh every quarter or after major product changes. Rerun the research pass, regenerate summaries, and archive outdated assumptions. The goal isn’t perfection; it’s keeping them relevant enough to guide decisions.
Bottom Line
Functional personas are faster to build, easier to maintain, and better aligned with real user behavior. By combining AI’s speed with human judgment, you can create personas that don’t just sit in a slide deck; they actively shape better products, clearer interfaces, and smoother experiences.
(yk)
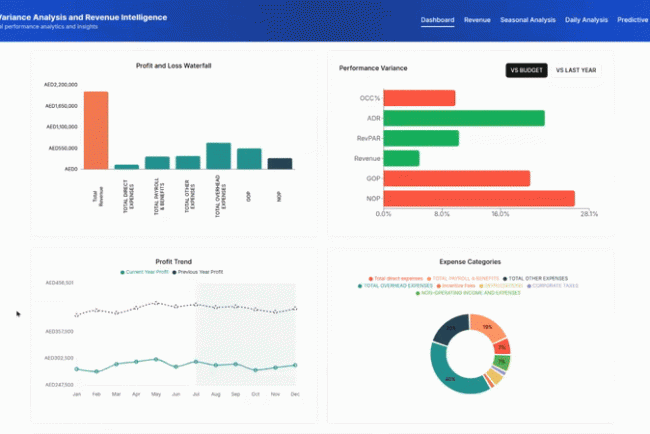
From Data To Decisions: UX Strategies For Real-Time Dashboards
From Data To Decisions: UX Strategies For Real-Time Dashboards From Data To Decisions: UX Strategies For Real-Time Dashboards Karan Rawal 2025-09-12T15:00:00+00:00 2025-09-17T15:32:19+00:00 I once worked with a fleet operations team that monitored dozens of vehicles in multiple cities. Their dashboard showed fuel consumption, live GPS […]
Accessibility
From Data To Decisions: UX Strategies For Real-Time Dashboards
Karan Rawal 2025-09-12T15:00:00+00:00
2025-09-17T15:32:19+00:00
I once worked with a fleet operations team that monitored dozens of vehicles in multiple cities. Their dashboard showed fuel consumption, live GPS locations, and real-time driver updates. Yet the team struggled to see what needed urgent attention. The problem was not a lack of data but a lack of clear indicators to support decision-making. There were no priorities, alerts, or context to highlight what mattered most at any moment.
Real-time dashboards are now critical decision-making tools in industries like logistics, manufacturing, finance, and healthcare. However, many of them fail to help users make timely and confident decisions, even when they show live data.
Designing for real-time use is very different from designing static dashboards. The challenge is not only presenting metrics but enabling decisions under pressure. Real-time users face limited time and a high cognitive load. They need clarity on actions, not just access to raw data.
This requires interface elements that support quick scanning, pattern recognition, and guided attention. Layout hierarchy, alert colors, grouping, and motion cues all help, but they must be driven by a deeper strategy: understanding what the user must decide in that moment.
This article explores practical UX strategies for real-time dashboards that enable real decisions. Instead of focusing only on visual best practices, it looks at how user intent, personalization, and cognitive flow can turn raw data into meaningful, timely insights.
Designing for Real-Time Comprehension: Helping Users Stay Focused Under Pressure
A GPS app not only shows users their location but also helps them decide where to go next. In the same way, a real-time dashboard should go beyond displaying the latest data. Its purpose is to help users quickly understand complex information and make informed decisions, especially in fast-paced environments with short attention spans.
How Users Process Real-Time Updates
Humans have limited cognitive capacity, so they can only process a small amount of data at once. Without proper context or visual cues, rapidly updating dashboards can overwhelm users and shift attention away from key information.
To address this, I use the following approaches:
- Delta Indicators and Trend Sparklines
Delta indicators show value changes at a glance, while sparklines are small line charts that reveal trends over time in a compact space. For example, a sales dashboard might show a green upward arrow next to revenue to indicate growth, along with a sparkline displaying sales trends over the past week. - Subtle Micro-Animations
Small animations highlight changes without distracting users. Research in cognitive psychology shows that such animations effectively draw attention, helping users notice updates while staying focused. For instance, a soft pulse around a changing metric can signal activity without overwhelming the viewer. - Mini-History Views
Showing a short history of recent changes reduces reliance on memory. For example, a dashboard might let users scroll back a few minutes to review updates, supporting better understanding and verification of data trends.
Common Challenges In Real-Time Dashboards
Many live dashboards fail when treated as static reports instead of dynamic tools for quick decision-making.
In my early projects, I made this mistake, resulting in cluttered layouts, distractions, and frustrated users.
Typical errors include the following:
- Overcrowded Interfaces: Presenting too many metrics competes for users’ attention, making it hard to focus.
- Flat Visual Hierarchy: Without clear emphasis on critical data, users might focus on less important information.
- No Record of Changes: When numbers update instantly with no explanation, users can feel lost or confused.
- Excessive Refresh Rates: Not all data needs constant updates. Updating too frequently can create unnecessary motion and cognitive strain.
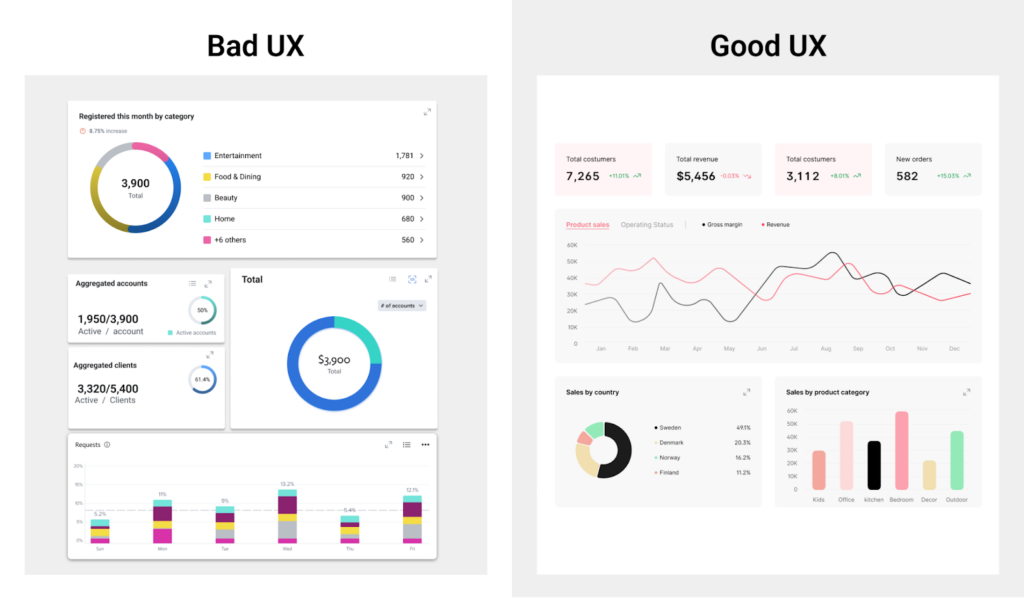{kind=link}

Managing Stress And Cognitive Overload
Under stress, users depend on intuition and focus only on immediately relevant information. If a dashboard updates too quickly or shows conflicting alerts, users may delay actions or make mistakes. It is important to:
- Prioritize the most important data first to avoid overwhelming the user.
- Offer snapshot or pause options so users can take time to process information.
- Use clear indicators to show if an action is required or if everything is operating normally.
In real-time environments, the best dashboards balance speed with calmness and clarity. They are not just data displays but tools that promote live thinking and better decisions.
“
Enabling Personalization For Effective Data Consumption
Many analytics tools let users build custom dashboards, but these design principles guide layouts that support decision-making. Personalization options such as custom metric selection, alert preferences, and update pacing help manage cognitive load and improve data interpretation.
| Cognitive Challenge | UX Risk in Real-Time Dashboards | Design Strategy to Mitigate |
|---|---|---|
| Users can’t track rapid changes | Confusion, missed updates, second-guessing | Use delta indicators, change animations, and trend sparklines |
| Limited working memory | Overload from too many metrics at once | Prioritize key KPIs, apply progressive disclosure |
| Visual clutter under stress | Tunnel vision or misprioritized focus | Apply a clear visual hierarchy, minimize non-critical elements |
| Unclear triggers or alerts | Decision delays, incorrect responses | Use thresholds, binary status indicators, and plain language |
| Lack of context/history | Misinterpretation of sudden shifts | Provide micro-history, snapshot freeze, or hover reveal |
Common Cognitive Challenges in Real-Time Dashboards and UX Strategies to Overcome Them.
Designing For Focus: Using Layout, Color, And Animation To Drive Real-Time Decisions
Layout, color, and animation do more than improve appearance. They help users interpret live data quickly and make decisions under time pressure. Since users respond to rapidly changing information, these elements must reduce cognitive load and highlight key insights immediately.
- Creating a Visual Hierarchy to Guide Attention.
A clear hierarchy directs users’ eyes to key metrics. Arrange elements so the most important data stands out. For example, place critical figures like sales volume or system health in the upper left corner to match common scanning patterns. Limit visible elements to about five to prevent overload and ease processing—group related data into cards to improve scannability and help users focus without distraction. - Using Color Purposefully to Convey Meaning.
Color communicates meaning in data visualization. Red or orange indicates critical alerts or negative trends, signaling urgency. Blue and green represent positive or stable states, offering reassurance. Neutral tones like gray support background data and make key colors stand out. Ensure accessibility with strong contrast and pair colors with icons or labels. For example, bright red can highlight outages while muted gray marks historical logs, keeping attention on urgent issues. - Supporting Comprehension with Subtle Animation.
Animation should clarify, not distract. Smooth transitions of 200 to 400 milliseconds communicate changes effectively. For instance, upward motion in a line chart reinforces growth. Hover effects and quick animations provide feedback and improve interaction. Thoughtful motion makes changes noticeable while maintaining focus.
{kind=link}

Layout, color, and animation create an experience that enables fast, accurate interpretation of live data. Real-time dashboards support continuous monitoring and decision-making by reducing mental effort and highlighting anomalies or trends. Personalization allows users to tailor dashboards to their roles, improving relevance and efficiency. For example, operations managers may focus on system health metrics while sales directors prioritize revenue KPIs. This adaptability makes dashboards dynamic, strategic tools.
| Element | Placement & Visual Weight | Purpose & Suggested Colors | Animation Use Case & Effect |
|---|---|---|---|
| Primary KPIs | Center or top-left; bold, large font | Highlight critical metrics; typically stable states | Value updates: smooth increase (200–400 ms) |
| Controls | Top or left panel; light, minimal visual weight | Provide navigation/filtering; neutral color schemes | User actions: subtle feedback (100–150 ms) |
| Charts | Middle or right; medium emphasis | Show trends and comparisons; use blue/green for positives, grey for neutral | Chart trends: trail or fade (300–600 ms) |
| Alerts | Edge of dashboard or floating; high contrast (bold) | Signal critical issues; red/orange for alerts, yellow/amber for warnings | Quick animations for appearance; highlight changes |
Design Elements, Placement, Color, and Motion Strategies for Effective Real-Time Dashboards.
Clarity In Motion: Designing Dashboards That Make Change Understandable
If users cannot interpret changes quickly, the dashboard fails regardless of its visual design. Over time, I have developed methods that reduce confusion and make change feel intuitive rather than overwhelming.
One of the most effective tools I use is the sparkline, a compact line chart that shows a trend over time and is typically placed next to a key performance indicator. Unlike full charts, sparklines omit axes and labels. Their simplicity makes them powerful, since they instantly show whether a metric is trending up, down, or steady. For example, placing a sparkline next to monthly revenue immediately reveals if performance is improving or declining, even before the viewer interprets the number.
When using sparklines effectively, follow these principles:
- Pair sparklines with metrics such as revenue, churn rate, or user activity so users can see both the value and its trajectory at a glance.
- Simplify by removing clutter like axis lines or legends unless they add real value.
- Highlight the latest data point with a dot or accent color since current performance often matters more than historical context.
- Limit the time span. Too many data points compress the sparkline and hurt readability. A focused window, such as the last 7 or 30 days, keeps the trend clear.
- Use sparklines in comparative tables. When placed in rows (for example, across product lines or regions), they reveal anomalies or emerging patterns that static numbers may hide.
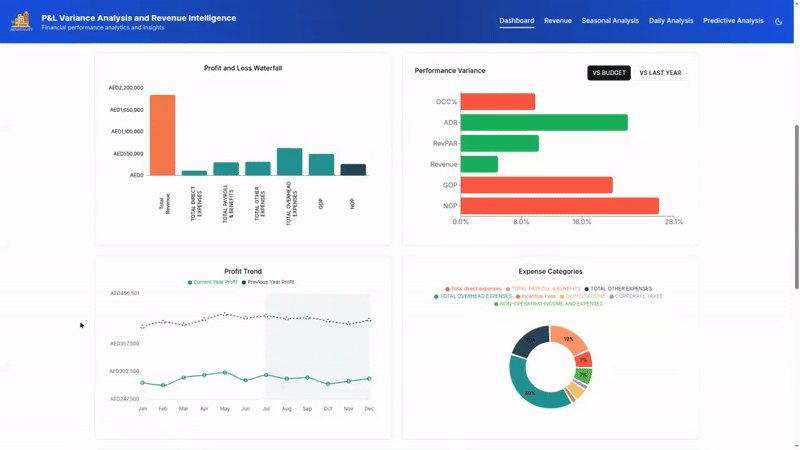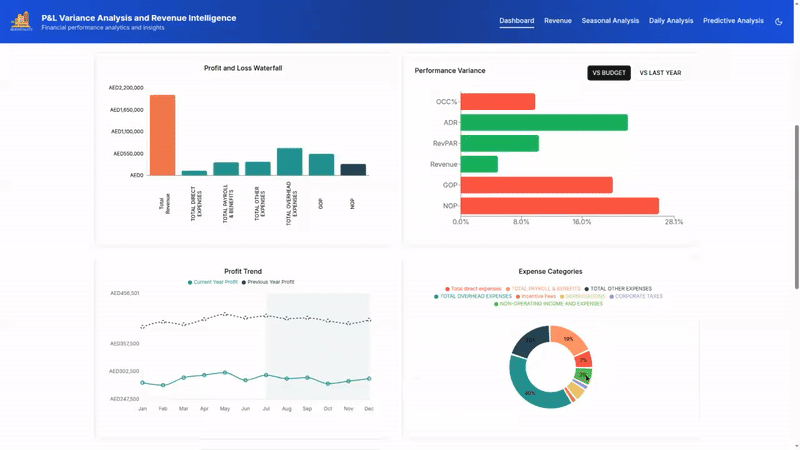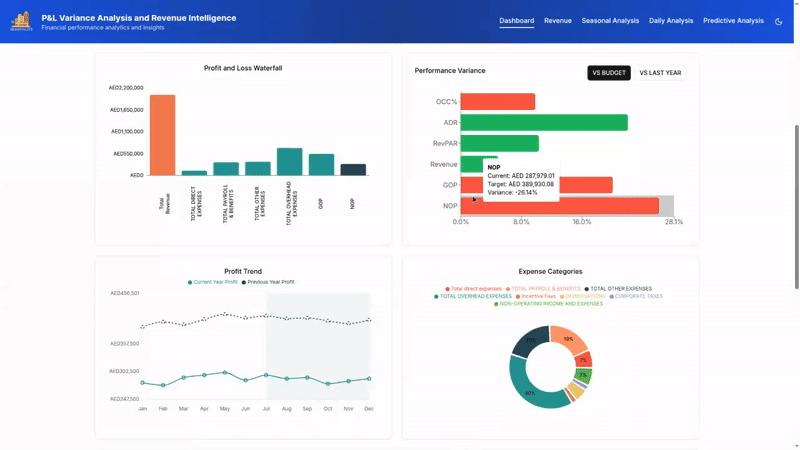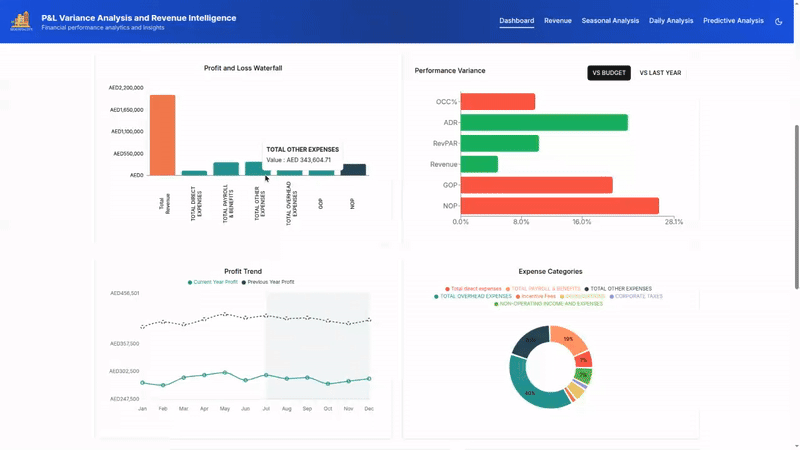
I combine sparklines with directional indicators like arrows and percentage deltas to support quick interpretation.
For example, pairing “▲ +3.2%” with a rising sparkline shows both the direction and scale of change. I do not rely only on color to convey meaning.
Since 1 in 12 men is color-blind, using red and green alone can exclude some users. To ensure accessibility, I add shapes and icons alongside color cues.
Micro-animations provide subtle but effective signals. This counters change blindness — our tendency to miss non-salient changes.
- When numbers update, I use fade-ins or count-up transitions to indicate change without distraction.
- If a list reorders, such as when top-performing teams shift positions, a smooth slide animation under 300 milliseconds helps users maintain spatial memory. These animations reduce cognitive friction and prevent disorientation.
Layout is critical for clarifying change:
- I use modular cards with consistent spacing, alignment, and hierarchy to highlight key metrics.
- Cards are arranged in a sortable grid, allowing filtering by severity, recency, or relevance.
- Collapsible sections manage dense information while keeping important data visible for quick scanning and deeper exploration.
For instance, in a logistics dashboard, a card labeled “On-Time Deliveries” may display a weekly sparkline. If performance dips, the line flattens or turns slightly red, a downward arrow appears with a −1.8% delta, and the updated number fades in. This gives instant clarity without requiring users to open a detailed chart.
All these design choices support fast, informed decision-making. In high-velocity environments like product analytics, logistics, or financial operations, dashboards must do more than present data. They must reduce ambiguity and help teams quickly detect change, understand its impact, and take action.
Making Reliability Visible: Designing for Trust In Real-Time Data Interfaces
In real-time data environments, reliability is not just a technical feature. It is the foundation of user trust. Dashboards are used in high-stakes, fast-moving contexts where decisions depend on timely, accurate data. Yet these systems often face less-than-ideal conditions such as unreliable networks, API delays, and incomplete datasets. Designing for these realities is not just damage control. It is essential for making data experiences usable and trustworthy.
When data lags or fails to load, it can mislead users in serious ways:
- A dip in a trendline may look like a market decline when it is only a delay in the stream.
- Missing categories in a bar chart, if not clearly signaled, can lead to flawed decisions.
To mitigate this:
- Every data point should be paired with its condition.
- Interfaces must show not only what the data says but also how current or complete it is.
One effective strategy is replacing traditional spinners with skeleton UIs. These are greyed-out, animated placeholders that suggest the structure of incoming data. They set expectations, reduce anxiety, and show that the system is actively working. For example, in a financial dashboard, users might see the outline of a candlestick chart filling in as new prices arrive. This signals that data is being refreshed, not stalled.
Handling Data Unavailability
When data is unavailable, I show cached snapshots from the most recent successful load, labeled with timestamps such as “Data as of 10:42 AM.” This keeps users aware of what they are viewing.
In operational dashboards such as logistics or monitoring systems, this approach lets users act confidently even when real-time updates are temporarily out of sync.
Managing Connectivity Failures
To handle connectivity failures, I use auto-retry mechanisms with exponential backoff, giving the system several chances to recover quietly before notifying the user.
If retries fail, I maintain transparency with clear banners such as “Offline… Reconnecting…” In one product, this approach prevented users from reloading entire dashboards unnecessarily, especially in areas with unreliable Wi-Fi.
Ensuring Reliability with Accessibility
Reliability strongly connects with accessibility:
- Real-time interfaces must announce updates without disrupting user focus, beyond just screen reader compatibility.
- ARIA live regions quietly narrate significant changes in the background, giving screen reader users timely updates without confusion.
- All controls remain keyboard-accessible.
- Animations follow motion-reduction preferences to support users with vestibular sensitivities.
Data Freshness Indicator
A compact but powerful pattern I often implement is the Data Freshness Indicator, a small widget that:
- Shows sync status,
- Displays the last updated time,
- Includes a manual refresh button.
This improves transparency and reinforces user control. Since different users interpret these cues differently, advanced systems allow personalization. For example:
- Analysts may prefer detailed logs of update attempts.
- Business users might see a simple status such as “Live”, “Stale”, or “Paused”.
Reliability in data visualization is not about promising perfection. It is about creating a resilient, informative experience that supports human judgment by revealing the true state of the system.
“
When users understand what the dashboard knows, what it does not, and what actions it is taking, they are more likely to trust the data and make smarter decisions.
Real-World Case Study
In my work across logistics, hospitality, and healthcare, the challenge has always been to distill complexity into clarity. A well-designed dashboard is more than functional; it serves as a trusted companion in decision-making, embedding clarity, speed, and confidence from the start.
1. Fleet Management Dashboard
A client in the car rental industry struggled with fragmented operational data. Critical details like vehicle locations, fuel usage, maintenance schedules, and downtime alerts were scattered across static reports, spreadsheets, and disconnected systems. Fleet operators had to manually cross-reference data sources, even for basic dispatch tasks, which caused missed warnings, inefficient routing, and delays in response.
We solved these issues by redesigning the dashboard strategically, focusing on both layout improvements and how users interpret and act on information.
Strategic Design Improvements and Outcomes:
- Instant visibility of KPIs
High-contrast cards at the top of the dashboard made key performance indicators instantly visible.
Example: Fuel consumption anomalies that previously went unnoticed for days were flagged within hours, enabling quick corrective action. - Clear trend and pattern visualization
Booking forecasts, utilization graphs, and city-by-city comparisons highlighted performance trends.
Example: A weekday-weekend booking chart helped a regional manager spot underperformance in one city and plan targeted vehicle redistribution. - Unified operational snapshot
Cost, downtime, and service schedules were grouped into one view.
Result: The operations team could assess fleet health in under five minutes each morning instead of using multiple tools. - Predictive context for planning
Visual cues showed peak usage periods and historical demand curves.
Result: Dispatchers prepared for forecasted spikes, reducing customer wait times and improving resource availability. - Live map with real-time status
A color-coded map displays vehicle status: green for active, red for urgent attention, gray for idle.
Result: Supervisors quickly identified inactive or delayed vehicles and rerouted resources as needed. - Role-based personalization
Personalization options were built in, allowing each role to customize dashboard views.
Example: Fleet managers prioritized financial KPIs, while technicians filtered for maintenance alerts and overdue service reports.
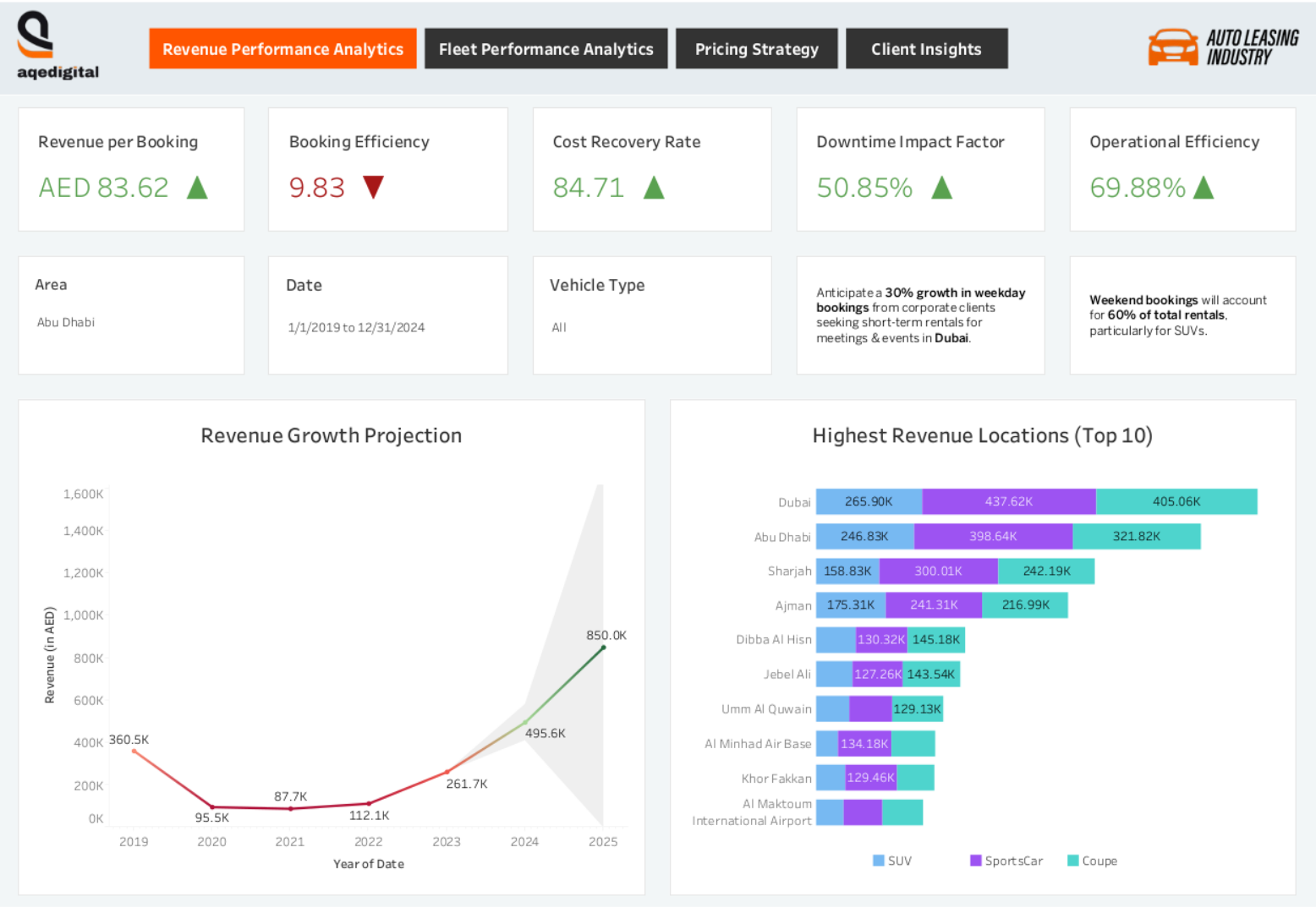{kind=link}

Strategic Impact: The dashboard redesign was not only about improving visuals. It changed how teams interacted with data. Operators no longer needed to search for insights, as the system presented them in line with tasks and decision-making. The dashboard became a shared reference for teams with different goals, enabling real-time problem solving, fewer manual checks, and stronger alignment across roles. Every element was designed to build both understanding and confidence in action.
2. Hospitality Revenue Dashboard
One of our clients, a hospitality group with 11 hotels in the UAE, faced a growing strategic gap. They had data from multiple departments, including bookings, events, food and beverage, and profit and loss, but it was spread across disconnected dashboards.
Strategic Design Improvements and Outcomes:
- All revenue streams (rooms, restaurants, bars, and profit and loss) were consolidated into a single filterable dashboard.
Example: A revenue manager could filter by property to see if a drop in restaurant revenue was tied to lower occupancy or was an isolated issue. The structure supported daily operations, weekly reviews, and quarterly planning. - Disconnected charts and metrics were replaced with a unified visual narrative showing how revenue streams interacted.
Example: The dashboard revealed how event bookings influenced bar sales or staffing. This shifted teams from passive data consumption to active interpretation. - AI modules for demand forecasting, spend prediction, and pricing recommendations were embedded in the dashboard.
Result: Managers could test rate changes with interactive sliders and instantly view effects on occupancy, revenue per available room, and food and beverage income. This enabled proactive scenario planning. - Compact, color-coded sparklines were placed next to each key metric to show short- and long-term trends.
Result: These visuals made it easy to spot seasonal shifts or channel-specific patterns without switching views or opening separate reports. - Predictive overlays such as forecast bands and seasonality markers were added to performance graphs.
Example: If occupancy rose but lagged behind seasonal forecasts, the dashboard surfaced the gap, prompting early action such as promotions or issue checks.
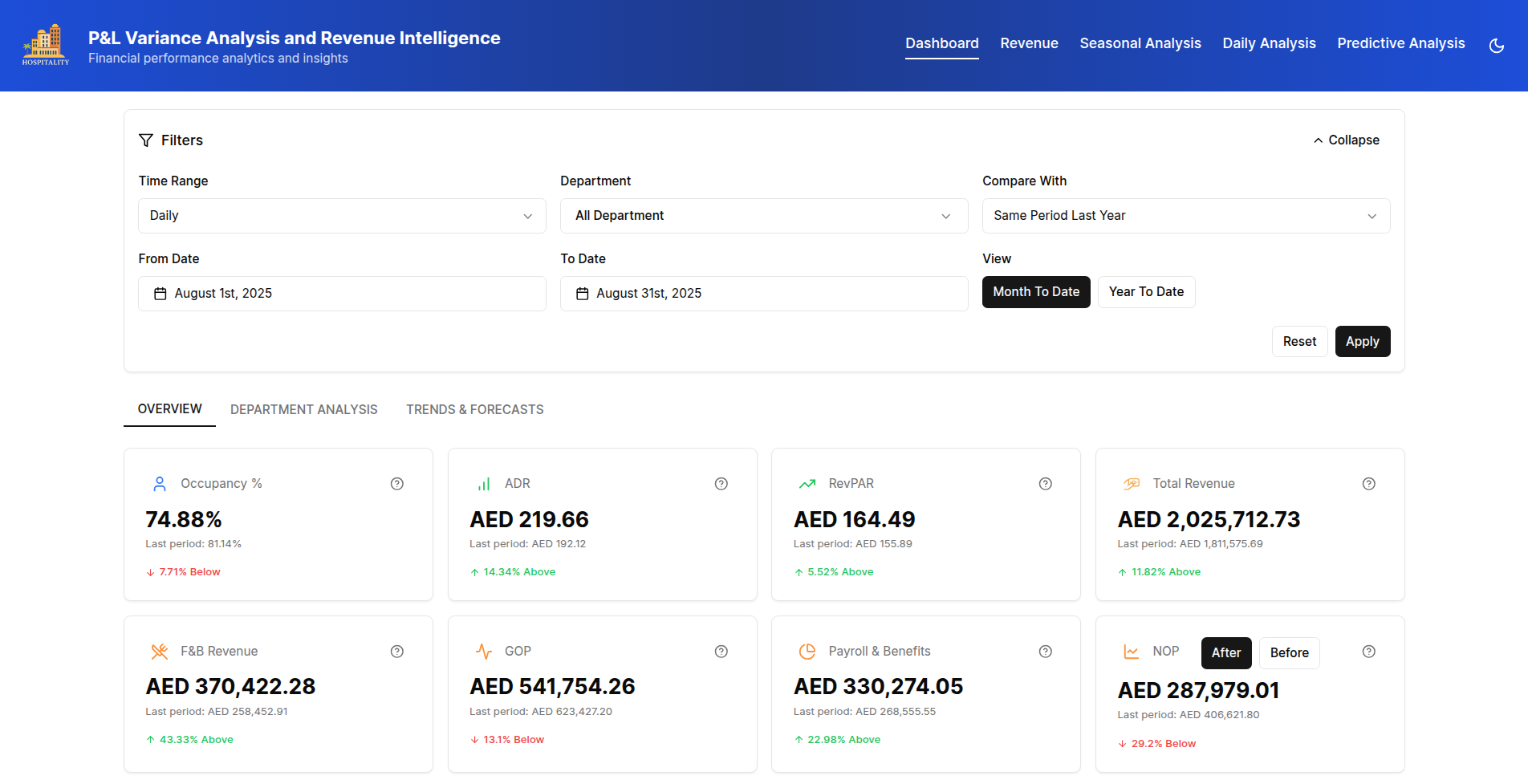{kind=link}

Strategic Impact: By aligning the dashboard structure with real pricing and revenue strategies, the client shifted from static reporting to forward-looking decision-making. This was not a cosmetic interface update. It was a complete rethinking of how data could support business goals. The result enabled every team, from finance to operations, to interpret data based on their specific roles and responsibilities.
3. Healthcare Interoperability Dashboard
In healthcare, timely and accurate access to patient information is essential. A multi-specialist hospital client struggled with fragmented data. Doctors had to consult separate platforms such as electronic health records, lab results, and pharmacy systems to understand a patient’s condition. This fragmented process slowed decision-making and increased risks to patient safety.
Strategic Design Improvements and Outcomes:
- Patient medical history was integrated to unify lab reports, medications, and allergy information in one view.
Example: A cardiologist, for example, could review recent cardiac markers with active medications and allergy alerts in the same place, enabling faster diagnosis and treatment. - Lab report tracking was upgraded to show test type, date, status, and a clear summary with labels such as Pending, Completed, and Awaiting Review.
Result: Trends were displayed with sparklines and color-coded indicators, helping clinicians quickly spot abnormalities or improvements. - A medication management module was added for prescription entry, viewing, and exporting. It included dosage, frequency, and prescribing physician details.
Example: Specialists could customize it to highlight drugs relevant to their practice, reducing overload and focusing on critical treatments. - Rapid filtering options were introduced to search by patient name, medical record number, date of birth, gender, last visit, insurance company, or policy number.
Example: Billing staff could locate patients by insurance details, while clinicians filtered records by visits or demographics. - Visual transparency was provided through interactive tooltips explaining alert rationales and flagged data points.
Result: Clinicians gained immediate context, such as the reason a lab value was marked as critical, supporting informed and timely decisions.
{kind=link}

Strategic Impact: Our design encourages active decision-making instead of passive data review. Interactive tooltips ensure visual transparency by explaining the rationale behind alerts and flagged data points. These information boxes give clinicians immediate context, such as why a lab value is marked critical, helping them understand implications and next steps without delay.
Key UX Insights from the Above 3 Examples
- Design should drive conclusions, not just display data.
Contextualized data enabled faster and more confident decisions. For example, a logistics dashboard flagged high-risk delays so dispatchers could act immediately. - Complexity should be structured, not eliminated.
Tools used timelines, layering, and progressive disclosure to handle dense information. A financial tool groups transactions by time blocks, easing cognitive load without losing detail. - Trust requires clear system logic.
Users trusted predictive alerts only after understanding their triggers. A healthcare interface added a “Why this alert?” option that explained the reasoning. - The aim is clarity and action, not visual polish.
Redesigns improved speed, confidence, and decision-making. In real-time contexts, confusion delays are more harmful than design flaws.
Final Takeaways
Real-time dashboards are not about overwhelming users with data. They are about helping them act quickly and confidently. The most effective dashboards reduce noise, highlight the most important metrics, and support decision-making in complex environments. Success lies in balancing visual clarity with cognitive ease while accounting for human limits like memory, stress, and attention alongside technical needs.
Do:
- Prioritize key metrics in a clear order so priorities are obvious. For instance, a support manager may track open tickets before response times.
- Use subtle micro-animations and small visual cues to indicate changes, helping users spot trends without distraction.
- Display data freshness and sync status to build trust.
- Plan for edge cases like incomplete or offline data to keep the experience consistent.
- Ensure accessibility with high contrast, ARIA labels, and keyboard navigation.
Don’t:
- Overcrowd the interface with too many metrics.
- Rely only on color to communicate critical information.
- Update all data at once or too often, which can cause overload.
- Hide failures or delays; transparency helps users adapt.
Over time, I’ve come to see real-time dashboards as decision assistants rather than control panels. When users say, “This helps me stay in control,” it reflects a design built on empathy that respects cognitive limits and enhances decision-making. That is the true measure of success.
(yk)
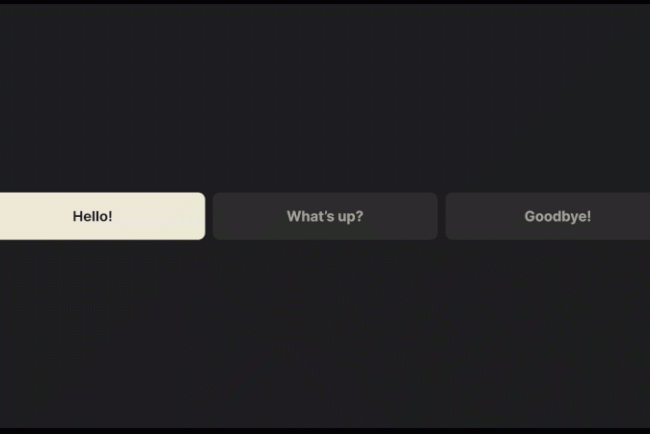
Designing For TV: Principles, Patterns And Practical Guidance (Part 2)
Designing For TV: Principles, Patterns And Practical Guidance (Part 2) Designing For TV: Principles, Patterns And Practical Guidance (Part 2) Milan Balać 2025-09-04T10:00:00+00:00 2025-09-10T15:02:59+00:00 Having covered the developmental history and legacy of TV in Part 1, let’s now delve into more practical matters. As a […]
Accessibility
Designing For TV: Principles, Patterns And Practical Guidance (Part 2)
Milan Balać 2025-09-04T10:00:00+00:00
2025-09-10T15:02:59+00:00
Having covered the developmental history and legacy of TV in Part 1, let’s now delve into more practical matters. As a quick reminder, the “10-foot experience” and its reliance on the six core buttons of any remote form the basis of our efforts, and as you’ll see, most principles outlined simply reinforce the unshakeable foundations.
In this article, we’ll sift through the systems, account for layout constraints, and distill the guidelines to understand the essence of TV interfaces. Once we’ve collected all the main ingredients, we’ll see what we can do to elevate these inherently simplistic experiences.
Let’s dig in, and let’s get practical!
The Systems
When it comes to hardware, TVs and set-top boxes are usually a few generations behind phones and computers. Their components are made to run lightweight systems optimised for viewing, energy efficiency, and longevity. Yet even within these constraints, different platforms offer varying performance profiles, conventions, and price points.
Some notable platforms/systems of today are:
- Roku, the most affordable and popular, but severely bottlenecked by weak hardware.
- WebOS, most common on LG devices, relies on web standards and runs well on modest hardware.
- Android TV, considered very flexible and customisable, but relatively demanding hardware-wise.
- Amazon Fire, based on Android but with a separate ecosystem. It offers great smooth performance, but is slightly more limited than stock Android.
- tvOS, by Apple, offering a high-end experience followed by a high-end price with extremely low customizability.
Despite their differences, all of the platforms above share something in common, and by now you’ve probably guessed that it has to do with the remote. Let’s take a closer look:
{kind=link}

If these remotes were stripped down to just the D-pad, OK, and BACK buttons, they would still be capable of successfully navigating any TV interface. It is this shared control scheme that allows for the agnostic approach of this article with broadly applicable guidelines, regardless of the manufacturer.
Having already discussed the TV remote in detail in Part 1, let’s turn to the second part of the equation: the TV screen, its layout, and the fundamental building blocks of TV-bound experiences.
TV Design Fundamentals
The Screen
With almost one hundred years of legacy, TV has accumulated quite some baggage. One recurring topic in modern articles on TV design is the concept of “overscan” — a legacy concept from the era of cathode ray tube (CRT) screens. Back then, the lack of standards in production meant that television sets would often crop the projected image at its edges. To address this inconsistency, broadcasters created guidelines to keep important content from being cut off.
{kind=link}

While overscan gets mentioned occasionally, we should call it what it really is — a thing of the past. Modern panels display content with greater precision, making thinking in terms of title and action safe areas rather archaic. Today, we can simply consider the margins and get the same results.
{kind=link}

Google calls for a 5% margin layout and Apple advises a 60-point margin top and bottom, and 80 points on the sides in their Layout guidelines. The standard is not exactly clear, but the takeaway is simple: leave some breathing room between screen edge and content, like you would in any thoughtful layout.
{kind=link}

Having left some baggage behind, we can start considering what to put within and outside the defined bounds.
The Layout
Considering the device is made for content consumption, streaming apps such as Netflix naturally come to mind. Broadly speaking, all these interfaces share a common layout structure where a vast collection of content is laid out in a simple grid.
{kind=link}

These horizontally scrolling groups (sometimes referred to as “shelves”) resemble rows of a bookcase. Typically, they’ll contain dozens of items that don’t fit into the initial “fold”, so we’ll make sure the last visible item “peeks” from the edge, subtly indicating to the viewer there’s more content available if they continue scrolling.
If we were to define a standard 12-column layout grid, with a 2-column-wide item, we’d end up with something like this:
{kind=link}

As you can see, the last item falls outside the “safe” zone.
Tip: A useful trick I discovered when designing TV interfaces was to utilise an odd number of columns. This allows the last item to fall within the defined margins and be more prominent while having little effect on the entire layout. We’ve concluded that overscan is not a prominent issue these days, yet an additional column in the layout helps completely circumvent it. Food for thought!
{kind=link}

Typography
TV design requires us to practice restraint, and this becomes very apparent when working with type. All good typography practices apply to TV design too, but I’d like to point out two specific takeaways.
First, accounting for the distance, everything (including type) needs to scale up. Where 16–18px might suffice for web baseline text, 24px should be your starting point on TV, with the rest of the scale increasing proportionally.
“Typography can become especially tricky in 10-ft experiences. When in doubt, go larger.”
— Molly Lafferty (Marvel Blog)
With that in mind, the second piece of advice would be to start with a small 5–6 size scale and adjust if necessary. The simplicity of a TV experience can, and should, be reflected in the typography itself, and while small, such a scale will do all the “heavy lifting” if set correctly.
{kind=link}

What you see in the example above is a scale I reduced from Google and Apple guidelines, with a few size adjustments. Simple as it is, this scale served me well for years, and I have no doubt it could do the same for you.
Freebie
If you’d like to use my basic reduced type scale Figma design file for kicking off your own TV project, feel free to do so!
{kind=link}

Color
Imagine watching TV at night with the device being the only source of light in the room. You open up the app drawer and select a new streaming app; it loads into a pretty splash screen, and — bam! — a bright interface opens up, which, amplified by the dark surroundings, blinds you for a fraction of a second. That right there is our main consideration when using color on TV.
Built for cinematic experiences and often used in dimly lit environments, TVs lend themselves perfectly to darker and more subdued interfaces. Bright colours, especially pure white (#ffffff), will translate to maximum luminance and may be straining on the eyes. As a general principle, you should rely on a more muted color palette. Slightly tinting brighter elements with your brand color, or undertones of yellow to imitate natural light, will produce less visually unsettling results.
Finally, without a pointer or touch capabilities, it’s crucial to clearly highlight interactive elements. While using bright colors as backdrops may be overwhelming, using them sparingly to highlight element states in a highly contrasting way will work perfectly.
This highlighting of UI elements is what TV leans on heavily — and it is what we’ll discuss next.
Focus
In Part 1, we have covered how interacting through a remote implies a certain detachment from the interface, mandating reliance on a focus state to carry the burden of TV interaction. This is done by visually accenting elements to anchor the user’s eyes and map any subsequent movement within the interface.
If you have ever written HTML/CSS, you might recall the use of the :focus CSS pseudo-class. While it’s primarily an accessibility feature on the web, it’s the core of interaction on TV, with more flexibility added in the form of two additional directions thanks to a dedicated D-pad.
Focus Styles
There are a few standard ways to style a focus state. Firstly, there’s scaling — enlarging the focused element, which creates the illusion of depth by moving it closer to the viewer.
Another common approach is to invert background and text colors.
Finally, a border may be added around the highlighted element.
These styles, used independently or in various combinations, appear in all TV interfaces. While execution may be constrained by the specific system, the purpose remains the same: clear and intuitive feedback, even from across the room.
Having set the foundations of interaction, layout, and movement, we can start building on top of them. The next chapter will cover the most common elements of a TV interface, their variations, and a few tips and tricks for button-bound navigation.
Common TV UI Components
Nowadays, the core user journey on television revolves around browsing (or searching through) a content library, selecting an item, and opening a dedicated screen to watch or listen.
This translates into a few fundamental screens:
- Library (or Home) for content browsing,
- Search for specific queries, and
- A player screen focused on content playback.
These screens are built with a handful of components optimized for the 10-foot experience, and while they are often found on other platforms too, it’s worth examining how they differ on TV.
Menus
Appearing as a horizontal bar along the top edge of the screen, or as a vertical sidebar, the menu helps move between the different screens of an app. While its orientation mostly depends on the specific system, it does seem TV favors the side menu a bit more.
{kind=link}

Both menu types share a common issue: the farther the user navigates away from the menu (vertically, toward the bottom for top-bars; and horizontally, toward the right for sidebars), the more button presses are required to get back to it. Fortunately, usually a Back button shortcut is added to allow for immediate menu focus, which greatly improves usability.
That said, the problem will arise a lot sooner for top menus, which, paired with the issue of having to hide or fade the element, makes a persistent sidebar a more common pick in TV user interfaces, and allows for a more consistent experience.
Shelves, Posters, And Cards
We’ve already mentioned shelves when covering layouts; now let’s shed some more light on this topic. The “shelves” (horizontally scrolling groups) form the basis of TV content browsing and are commonly populated with posters in three different aspect ratios: 2:3, 16:9, and 1:1.
2:3 posters are common in apps specializing in movies and shows. Their vertical orientation references traditional movie posters, harkening back to the cinematic experiences TVs are built for. Moreover, their narrow shape allows more items to be immediately visible in a row, and they rarely require any added text, with titles baked into the poster image.
{kind=link}

16:9 posters abide by the same principles but with a horizontal orientation. They are often paired with text labels, which effectively turn them into cards, commonly seen on platforms like YouTube. In the absence of dedicated poster art, they show stills or playback from the videos, matching the aspect ratio of the media itself.
{kind=link}

1:1 posters are often found in music apps like Spotify, their shape reminiscent of album art and vinyl sleeves. These squares often get used in other instances, like representing channel links or profile tiles, giving more visual variety to the interface.
{kind=link}

All of the above can co-exist within a single app, allowing for richer interfaces and breaking up otherwise uniform content libraries.
And speaking of breaking up content, let’s see what we can do with spotlights!
Spotlights
Typically taking up the entire width of the screen, these eye-catching components will highlight a new feature or a promoted piece of media. In a sea of uniform shelves, they can be placed strategically to introduce aesthetic diversity and disrupt the monotony.
{kind=link}

A spotlight can be a focusable element by itself, or it could expose several actions thanks to its generous space. In my ventures into TV design, I relied on a few different spotlight sizes, which allowed me to place multiples into a single row, all with the purpose of highlighting different aspects of the app, without breaking the form to which viewers were used.
{kind=link}

{kind=link}

Posters, cards, and spotlights shape the bulk of the visual experience and content presentation, but viewers still need a way to find specific titles. Let’s see how search and input are handled on TV.
Search And Entering Text
Manually browsing through content libraries can yield results, but having the ability to search will speed things up — though not without some hiccups.
TVs allow for text input in the form of on-screen keyboards, similar to the ones found in modern smartphones. However, inputting text with a remote control is quite inefficient given the restrictiveness of its control scheme. For example, typing “hey there” on a mobile keyboard requires 9 keystrokes, but about 38 on a TV (!) due to the movement between characters and their selection.
Typing with a D-pad may be an arduous task, but at the same time, having the ability to search is unquestionably useful.
{kind=link}

Luckily for us, keyboards are accounted for in all systems and usually come in two varieties. We’ve got the grid layouts used by most platforms and a horizontal layout in support of the touch-enabled and gesture-based controls on tvOS. Swiping between characters is significantly faster, but this is yet another pattern that can only be enhanced, not replaced.
{kind=link}

Modernization has made things significantly easier, with search autocomplete suggestions, device pairing, voice controls, and remotes with physical keyboards, but on-screen keyboards will likely remain a necessary fallback for quite a while. And no matter how cumbersome this fallback may be, we as designers need to consider it when building for TV.
“
Players And Progress Bars
While all the different sections of a TV app serve a purpose, the Player takes center stage. It’s where all the roads eventually lead to, and where viewers will spend the most time. It’s also one of the rare instances where focus gets lost, allowing for the interface to get out of the way of enjoying a piece of content.
Arguably, players are the most complex features of TV apps, compacting all the different functionalities into a single screen. Take YouTube, for example, its player doesn’t just handle expected playback controls but also supports content browsing, searching, reading comments, reacting, and navigating to channels, all within a single screen.
{kind=link}

Compared to YouTube, Netflix offers a very lightweight experience guided by the nature of the app.
Still, every player has a basic set of controls, the foundation of which is the progress bar.
{kind=link}

The progress bar UI element serves as a visual indicator for content duration. During interaction, focus doesn’t get placed on the bar itself, but on a movable knob known as the “scrubber.” It is by moving the scrubber left and right, or stopping it in its tracks, that we can control playback.
Another indirect method of invoking the progress bar is with the good old Play and Pause buttons. Rooted in the mechanical era of tape players, the universally understood triangle and two vertical bars are as integral to the TV legacy as the D-pad. No matter how minimalist and sleek the modern player interface may be, these symbols remain a staple of the viewing experience.
{kind=link}

.jpg){kind=link}
The presence of a scrubber may also indicate the type of content. Video on demand allows for the full set of playback controls, while live streams (unless DVR is involved) will do away with the scrubber since viewers won’t be able to rewind or fast-forward.
Earlier iterations of progress bars often came bundled with a set of playback control buttons, but as viewers got used to the tools available, these controls often got consolidated into the progress bar and scrubber themselves.
Bringing It All Together
With the building blocks out of the box, we’ve got everything necessary for a basic but functional TV app. Just as the six core buttons make remote navigation possible, the components and principles outlined above help guide purposeful TV design. The more context you bring, the more you’ll be able to expand and combine these basic principles, creating an experience unique to your needs.
Before we wrap things up, I’d like to share a few tips and tricks I discovered along the way — tips and tricks which I wish I had known from the start. Regardless of how simple or complex your idea may be, these may serve you as useful tools to help add depth, polish, and finesse to any TV experience.
Thinking Beyond The Basics
Like any platform, TV has a set of constraints that we abide by when designing. But sometimes these norms are applied without question, making the already limited capabilities feel even more restraining. Below are a handful of less obvious ideas that can help you design more thoughtfully and flexibly for the big screen.
Long Press
Most modern remotes support press-and-hold gestures as a subtle way to enhance the functionality, especially on remotes with fewer buttons available.
For example, holding directional buttons when browsing content speeds up scrolling, while holding Left/Right during playback speeds up timeline seeking. In many apps, a single press of the OK button opens a video, but holding it for longer opens a contextual menu with additional actions.
While not immediately apparent, press-and-hold is often used in many instances of TV experiences, essentially doubling the capabilities of a single button. Depending on context, you can map certain buttons to have an additional action and give more depth to the interface without making it convoluted.
And speaking of mapping, let’s see how we can utilize it to our benefit.
Remapping Keys And The Importance Of Context
While not as flexible as long-press, button functions can be contextually remapped. For example, Amazon’s Prime Video maps the Up button to open its X-Ray feature during playback. Typically, all directional buttons open video controls, so repurposing one for a custom feature cleverly adds interactivity with little tradeoff.
{kind=link}

With limited input, context becomes a powerful tool. It not only declutters the interface to allow for more focus on specific tasks, but also enables the same set of buttons to trigger different actions based on the viewer’s location within an app.
“
Another great example is YouTube’s scrubber interaction. Once the scrubber is moved, every other UI element fades. This cleans up the viewer’s working area, so to speak, narrowing the interface to a single task. In this state — and only in this state — pressing Up one more time moves away from scrubbing and into browsing by chapter.
This is such an elegant example of expanding restraint, and adding more only when necessary. I hope it inspires similar interactions in your TV app designs.
Efficient Movement On TV
At its best, every action on TV “costs” at least one click. There’s no such thing as aimless cursor movement — if you want to move, you must press a button. We’ve seen how cumbersome it can be inside a keyboard, but there’s also something we can learn about efficient movement in these restrained circumstances.
Going back to the Homescreen, we can note that vertical and horizontal movement serve two distinct roles. Vertical movement switches between groups, while horizontal movement switches items within these groups. No matter how far you’ve gone inside a group, a single vertical click will move you into another.
This subtle difference — two axes with separate roles — is the most efficient way of moving in a TV interface. Reversing the pattern: horizontal to switch groups, and vertical to drill down, will work like a charm as long as you keep the role of each axis well defined.
Quietly brilliant and easy to overlook, this pattern powers almost every step of the TV experience. Remember it, and use it well.
Thinking Beyond JPGs
After covering in detail many of the technicalities, let’s finish with some visual polish.
Most TV interfaces are driven by tightly packed rows of cover and poster art. While often beautifully designed, this type of content and layouts leave little room for visual flair. For years, the flat JPG, with its small file size, has been a go-to format, though contemporary alternatives like WebP are slowly taking its place.
Meanwhile, we can rely on the tried and tested PNG to give a bit more shine to our TV interfaces. The simple fact that it supports transparency can help the often-rigid UIs feel more sophisticated. Used strategically and paired with simple focus effects such as background color changes, PNGs can bring subtle moments of delight to the interface.
Moreover, if transformations like scaling and rotating are supported, you can really make those rectangular shapes come alive with layering multiple assets.
As you probably understand by now, these little touches of finesse don’t go out of bounds of possibility. They simply find more room to breathe within it. But with such limited capabilities, it’s best to learn all the different tricks that can help make your TV experiences stand out.
Closing Thoughts
Rooted in legacy, with a limited control scheme and a rather “shallow” interface, TV design reminds us to do the best with what we have at our disposal. The restraints I outlined are not meant to induce claustrophobia and make you feel limited in your design choices, but rather to serve you as guides. It is by accepting that fact that we can find freedom and new avenues to explore.
This two-part series of articles, just like my experience designing for TV, was not about reinventing the wheel with radical ideas. It was about understanding its nuances and contributing to what’s already there with my personal touch.
If you find yourself working in this design field, I hope my guide will serve as a warm welcome and will help you do your finest work. And if you have any questions, do leave a comment, and I will do my best to reply and help.
Good luck!
Further Reading
- “Design for TV,” by Android Developers
Great TV design is all about putting content front and center. It’s about creating an interface that’s easier to use and navigate, even from a distance. It’s about making it easier to find the content you love, and to enjoy it in the best possible quality. - “TV Guidelines: A quick kick-off on designing for Television Experiences,” by Andrea Pacheco
Just like designing a mobile app, designing a TV application can be a fun and complex thing to do, due to the numerous guidelines and best practices to follow. Below, I have listed the main best practices to keep in mind when designing an app for a 10-foot screen. - “Designing for Television – TV Ui design,” by Molly Lafferty
We’re no longer limited to a remote and cable box to control our TVs; we’re using Smart TVs, or streaming from set-top boxes like Roku and Apple TV, or using video game consoles like Xbox and PlayStation. And each of these devices allows a user interface that’s much more powerful than your old-fashioned on-screen guide. - “Rethinking User Interface Design for the TV Platform,” by Pascal Potvin
Designing for television has become part of the continuum of devices that require a rethink of how we approach user interfaces and user experiences. - “Typography for TV,” by Android Developers
As television screens are typically viewed from a distance, interfaces that use larger typography are more legible and comfortable for users. TV Design’s default type scale includes contrasting and flexible type styles to support a wide range of use cases. - “Typography,” by Apple Developer docs
Your typographic choices can help you display legible text, convey an information hierarchy, communicate important content, and express your brand or style. - “Color on TV,” by Android Developers
Color on TV design can inspire, set the mood, and even drive users to make decisions. It’s a powerful and tangible element that users notice first. As a rich way to connect with a wide audience, it’s no wonder color is an important step in crafting a high-quality TV interface. - “Designing for Television — TV UI Design,” by Molly Lafferty (Marvel Blog)
Today, we’re no longer limited to a remote and cable box to control our TVs; we’re using Smart TVs, or streaming from set-top boxes like Roku and Apple TV, or using video game consoles like Xbox and PlayStation. And each of these devices allows a user interface that’s much more powerful than your old-fashioned on-screen guide.
(mb, yk)
Prompting Is A Design Act: How To Brief, Guide And Iterate With AI
Prompting Is A Design Act: How To Brief, Guide And Iterate With AI Prompting Is A Design Act: How To Brief, Guide And Iterate With AI Lyndon Cerejo 2025-08-29T10:00:00+00:00 2025-09-03T15:02:57+00:00 In “A Week In The Life Of An AI-Augmented Designer”, we followed Kate’s weeklong journey […]
Accessibility
Prompting Is A Design Act: How To Brief, Guide And Iterate With AI
Lyndon Cerejo 2025-08-29T10:00:00+00:00
2025-09-03T15:02:57+00:00
In “A Week In The Life Of An AI-Augmented Designer”, we followed Kate’s weeklong journey of her first AI-augmented design sprint. She had three realizations through the process:
- AI isn’t a co-pilot (yet); it’s more like a smart, eager intern.
One with access to a lot of information, good recall, fast execution, but no context. That mindset defined how she approached every interaction with AI: not as magic, but as management. - Don’t trust; guide, coach, and always verify.
Like any intern, AI needs coaching and supervision, and that’s where her designerly skills kicked in. Kate relied on curiosity to explore, observation to spot bias, empathy to humanize the output, and critical thinking to challenge what didn’t feel right. Her learning mindset helped her keep up with advances, and experimentation helped her learn by doing. - Prompting is part creative brief, and part conversation design, just with an AI instead of a person.
When you prompt an AI, you’re not just giving instructions, but designing how it responds, behaves, and outputs information. If AI is like an intern, then the prompt is your creative brief that frames the task, sets the tone, and clarifies what good looks like. It’s also your conversation script that guides how it responds, how the interaction flows, and how ambiguity is handled.
As designers, we’re used to designing interactions for people. Prompting is us designing our own interactions with machines — it uses the same mindset with a new medium. It shapes an AI’s behavior the same way you’d guide a user with structure, clarity, and intent.
If you’ve bookmarked, downloaded, or saved prompts from others, you’re not alone. We’ve all done that during our AI journeys. But while someone else’s prompts are a good starting point, you will get better and more relevant results if you can write your own prompts tailored to your goals, context, and style. Using someone else’s prompt is like using a Figma template. It gets the job done, but mastery comes from understanding and applying the fundamentals of design, including layout, flow, and reasoning. Prompts have a structure too. And when you learn it, you stop guessing and start designing.
Note: All prompts in this article were tested using ChatGPT — not because it’s the only game in town, but because it’s friendly, flexible, and lets you talk like a person, yes, even after the recent GPT-5 “update”. That said, any LLM with a decent attention span will work. Results for the same prompt may vary based on the AI model you use, the AI’s training, mood, and how confidently it can hallucinate.
Privacy PSA: As always, don’t share anything you wouldn’t want leaked, logged, or accidentally included in the next AI-generated meme. Keep it safe, legal, and user-respecting.
With that out of the way, let’s dive into the mindset, anatomy, and methods of effective prompting as another tool in your design toolkit.
Mindset: Prompt Like A Designer
As designers, we storyboard journeys, wireframe interfaces to guide users, and write UX copy with intention. However, when prompting AI, we treat it differently: “Summarize these insights”, “Make this better”, “Write copy for this screen”, and then wonder why the output feels generic, off-brand, or just meh. It’s like expecting a creative team to deliver great work from a one-line Slack message. We wouldn’t brief a freelancer, much less an intern, with “Design a landing page,” so why brief AI that way?
Prompting Is A Creative Brief For A Machine
Think of a good prompt as a creative brief, just for a non-human collaborator. It needs similar elements, including a clear role, defined goal, relevant context, tone guidance, and output expectations. Just as a well-written creative brief unlocks alignment and quality from your team, a well-structured prompt helps the AI meet your expectations, even though it doesn’t have real instincts or opinions.
Prompting Is Also Conversation Design
A good prompt goes beyond defining the task and sets the tone for the exchange by designing a conversation: guiding how the AI interprets, sequences, and responds. You shape the flow of tasks, how ambiguity is handled, and how refinement happens — that’s conversation design.
Anatomy: Structure It Like A Designer
So how do you write a designer-quality prompt? That’s where the W.I.R.E.+F.R.A.M.E. prompt design framework comes in — a UX-inspired framework for writing intentional, structured, and reusable prompts. Each letter represents a key design direction, grounded in the way UX designers already think: Just as a wireframe doesn’t dictate final visuals, this WIRE+FRAME framework doesn’t constrain creativity, but guides the AI with structured information it needs.
“Why not just use a series of back-and-forth chats with AI?”
You can, and many people do. But without structure, AI fills in the gaps on its own, often with vague or generic results. A good prompt upfront saves time, reduces trial and error, and improves consistency. And whether you’re working on your own or across a team, a framework means you’re not reinventing a prompt every time but reusing what works to get better results faster.
Just as we build wireframes before adding layers of fidelity, the WIRE+FRAME framework has two parts:
- WIRE is the must-have skeleton. It gives the prompt its shape.
- FRAME is the set of enhancements that bring polish, logic, tone, and reusability — like building a high-fidelity interface from the wireframe.
Let’s improve Kate’s original research synthesis prompt (“Read this customer feedback and tell me how we can improve financial literacy for Gen Z in our app”). To better reflect how people actually prompt in practice, let’s tweak it to a more broadly applicable version: “Read this customer feedback and tell me how we can improve our app for Gen Z users.” This one-liner mirrors the kinds of prompts we often throw at AI tools: short, simple, and often lacking structure.
Now, we’ll take that prompt and rebuild it using the first four elements of the W.I.R.E. framework — the core building blocks that provide AI with the main information it needs to deliver useful results.
W: Who & What
Define who the AI should be, and what it’s being asked to deliver.
A creative brief starts with assigning the right hat. Are you briefing a copywriter? A strategist? A product designer? The same logic applies here. Give the AI a clear identity and task. Treat AI like a trusted freelancer or intern. Instead of saying “help me”, tell it who it should act as and what’s expected.
Example: “You are a senior UX researcher and customer insights analyst. You specialize in synthesizing qualitative data from diverse sources to identify patterns, surface user pain points, and map them across customer journey stages. Your outputs directly inform product, UX, and service priorities.”
I: Input Context
Provide background that frames the task.
Creative partners don’t work in a vacuum. They need context: the audience, goals, product, competitive landscape, and what’s been tried already. This is the “What you need to know before you start” section of the brief. Think: key insights, friction points, business objectives. The same goes for your prompt.
Example: “You are analyzing customer feedback for Fintech Brand’s app, targeting Gen Z users. Feedback will be uploaded from sources such as app store reviews, survey feedback, and usability test transcripts.”
R: Rules & Constraints
Clarify any limitations, boundaries, and exclusions.
Good creative briefs always include boundaries — what to avoid, what’s off-brand, or what’s non-negotiable. Things like brand voice guidelines, legal requirements, or time and word count limits. Constraints don’t limit creativity — they focus it. AI needs the same constraints to avoid going off the rails.
Example: “Only analyze the uploaded customer feedback data. Do not fabricate pain points, representative quotes, journey stages, or patterns. Do not supplement with prior knowledge or hypothetical examples. Use clear, neutral, stakeholder-facing language.”
E: Expected Output
Spell out what the deliverable should look like.
This is the deliverable spec: What does the finished product look like? What tone, format, or channel is it for? Even if the task is clear, the format often isn’t. Do you want bullet points or a story? A table or a headline? If you don’t say, the AI will guess, and probably guess wrong. Even better, include an example of the output you want, an effective way to help AI know what you’re expecting. If you’re using GPT-5, you can also mix examples across formats (text, images, tables) together.
Example: “Return a structured list of themes. For each theme, include:
- Theme Title
- Summary of the Issue
- Problem Statement
- Opportunity
- Representative Quotes (from data only)
- Journey Stage(s)
- Frequency (count from data)
- Severity Score (1–5) where 1 = Minor inconvenience or annoyance; 3 = Frustrating but workaround exists; 5 = Blocking issue
- Estimated Effort (Low / Medium / High), where Low = Copy or content tweak; Medium = Logic/UX/UI change; High = Significant changes.”
WIRE gives you everything you need to stop guessing and start designing your prompts with purpose. When you start with WIRE, your prompting is like a briefing, treating AI like a collaborator.
Once you’ve mastered this core structure, you can layer in additional fidelity, like tone, step-by-step flow, or iterative feedback, using the FRAME elements. These five elements provide additional guidance and clarity to your prompt by layering clear deliverables, thoughtful tone, reusable structure, and space for creative iteration.
F: Flow of Tasks
Break complex prompts into clear, ordered steps.
This is your project plan or creative workflow that lays out the stages, dependencies, or sequence of execution. When the task has multiple parts, don’t just throw it all into one sentence. You are doing the thinking and guiding AI. Structure it like steps in a user journey or modules in a storyboard. In this example, it fits as the blueprint for the AI to use to generate the table described in “E: Expected Output”
Example: “Recommended flow of tasks:
Step 1: Parse the uploaded data and extract discrete pain points.
Step 2: Group them into themes based on pattern similarity.
Step 3: Score each theme by frequency (from data), severity (based on content), and estimated effort.
Step 4: Map each theme to the appropriate customer journey stage(s).
Step 5: For each theme, write a clear problem statement and opportunity based only on what’s in the data.”
R: Reference Voice or Style
Name the desired tone, mood, or reference brand.
This is the brand voice section or style mood board — reference points that shape the creative feel. Sometimes you want buttoned-up. Other times, you want conversational. Don’t assume the AI knows your tone, so spell it out.
Example: “Use the tone of a UX insights deck or product research report. Be concise, pattern-driven, and objective. Make summaries easy to scan by product managers and design leads.”
A: Ask for Clarification
Invite the AI to ask questions before generating, if anything is unclear.
This is your “Any questions before we begin?” moment — a key step in collaborative creative work. You wouldn’t want a freelancer to guess what you meant if the brief was fuzzy, so why expect AI to do better? Ask AI to reflect or clarify before jumping into output mode.
Example: “If the uploaded data is missing or unclear, ask for it before continuing. Also, ask for clarification if the feedback format is unstructured or inconsistent, or if the scoring criteria need refinement.”
M: Memory (Within The Conversation)
Reference earlier parts of the conversation and reuse what’s working.
This is similar to keeping visual tone or campaign language consistent across deliverables in a creative brief. Prompts are rarely one-shot tasks, so this reminds AI of the tone, audience, or structure already in play. GPT-5 got better with memory, but this still remains a useful element, especially if you switch topics or jump around.
Example: “Unless I say otherwise, keep using this process: analyze the data, group into themes, rank by importance, then suggest an action for each.”
E: Evaluate & Iterate
Invite the AI to critique, improve, or generate variations.
This is your revision loop — your way of prompting for creative direction, exploration, and refinement. Just like creatives expect feedback, your AI partner can handle review cycles if you ask for them. Build iteration into the brief to get closer to what you actually need. Sometimes, you may see ChatGPT test two versions of a response on its own by asking for your preference.
Example: “After listing all themes, identify the one with the highest combined priority score (based on frequency, severity, and effort).
For that top-priority theme:
- Critically evaluate its framing: Is the title clear? Are the quotes strong and representative? Is the journey mapping appropriate?
- Suggest one improvement (e.g., improved title, more actionable implication, clearer quote, tighter summary).
- Rewrite the theme entry with that improvement applied.
- Briefly explain why the revision is stronger and more useful for product or design teams.”
Here’s a quick recap of the WIRE+FRAME framework:
| Framework Component | Description |
|---|---|
| W: Who & What | Define the AI persona and the core deliverable. |
| I: Input Context | Provide background or data scope to frame the task. |
| R: Rules & Constraints | Set boundaries |
| E: Expected Output | Spell out the format and fields of the deliverable. |
| F: Flow of Tasks | Break the work into explicit, ordered sub-tasks. |
| R: Reference Voice/Style | Name the tone, mood, or reference brand to ensure consistency. |
| A: Ask for Clarification | Invite AI to pause and ask questions if any instructions or data are unclear before proceeding. |
| M: Memory | Leverage in-conversation memory to recall earlier definitions, examples, or phrasing without restating them. |
| E: Evaluate & Iterate | After generation, have the AI self-critique the top outputs and refine them. |
And here’s the full WIRE+FRAME prompt:
(W) You are a senior UX researcher and customer insights analyst. You specialize in synthesizing qualitative data from diverse sources to identify patterns, surface user pain points, and map them across customer journey stages. Your outputs directly inform product, UX, and service priorities.
(I) You are analyzing customer feedback for Fintech Brand’s app, targeting Gen Z users. Feedback will be uploaded from sources such as app store reviews, survey feedback, and usability test transcripts.
(R) Only analyze the uploaded customer feedback data. Do not fabricate pain points, representative quotes, journey stages, or patterns. Do not supplement with prior knowledge or hypothetical examples. Use clear, neutral, stakeholder-facing language.
(E) Return a structured list of themes. For each theme, include:
- Theme Title
- Summary of the Issue
- Problem Statement
- Opportunity
- Representative Quotes (from data only)
- Journey Stage(s)
- Frequency (count from data)
- Severity Score (1–5) where 1 = Minor inconvenience or annoyance; 3 = Frustrating but workaround exists; 5 = Blocking issue
- Estimated Effort (Low / Medium / High), where Low = Copy or content tweak; Medium = Logic/UX/UI change; High = Significant changes
(F) Recommended flow of tasks:
Step 1: Parse the uploaded data and extract discrete pain points.
Step 2: Group them into themes based on pattern similarity.
Step 3: Score each theme by frequency (from data), severity (based on content), and estimated effort.
Step 4: Map each theme to the appropriate customer journey stage(s).
Step 5: For each theme, write a clear problem statement and opportunity based only on what’s in the data.(R) Use the tone of a UX insights deck or product research report. Be concise, pattern-driven, and objective. Make summaries easy to scan by product managers and design leads.
(A) If the uploaded data is missing or unclear, ask for it before continuing. Also, ask for clarification if the feedback format is unstructured or inconsistent, or if the scoring criteria need refinement.
(M) Unless I say otherwise, keep using this process: analyze the data, group into themes, rank by importance, then suggest an action for each.
(E) After listing all themes, identify the one with the highest combined priority score (based on frequency, severity, and effort).
For that top-priority theme:
- Critically evaluate its framing: Is the title clear? Are the quotes strong and representative? Is the journey mapping appropriate?
- Suggest one improvement (e.g., improved title, more actionable implication, clearer quote, tighter summary).
- Rewrite the theme entry with that improvement applied.
- Briefly explain why the revision is stronger and more useful for product or design teams.
You could use “##” to label the sections (e.g., “##FLOW”) more for your readability than for AI. At over 400 words, this Insights Synthesis prompt example is a detailed, structured prompt, but it isn’t customized for you and your work. The intent wasn’t to give you a specific prompt (the proverbial fish), but to show how you can use a prompt framework like WIRE+FRAME to create a customized, relevant prompt that will help AI augment your work (teaching you to fish).
Keep in mind that prompt length isn’t a common concern, but rather a lack of quality and structure is. As of the time of writing, AI models can easily process prompts that are thousands of words long.
Not every prompt needs all the FRAME components; WIRE is often enough to get the job done. But when the work is strategic or highly contextual, pick components from FRAME — the extra details can make a difference. Together, WIRE+FRAME give you a detailed framework for creating a well-structured prompt, with the crucial components first, followed by optional components:
- WIRE builds a clear, focused prompt with role, input, rules, and expected output.
- FRAME adds refinement like tone, reusability, and iteration.
Here are some scenarios and recommendations for using WIRE or WIRE+FRAME:
| Scenarios | Description | Recommended |
|---|---|---|
| Simple, One-Off Analyses | Quick prompting with minimal setup and no need for detailed process transparency. | WIRE |
| Tight Sprints or Hackathons | Rapid turnarounds, and times you don’t need embedded review and iteration loops. | WIRE |
| Highly Iterative Exploratory Work | You expect to tweak results constantly and prefer manual control over each step. | WIRE |
| Complex Multi-Step Playbooks | Detailed workflows that benefit from a standardized, repeatable, visible sequence. | WIRE+FRAME |
| Shared or Hand-Off Projects | When different teams will rely on embedded clarification, memory, and consistent task flows for recurring analyses. | WIRE+FRAME |
| Built-In Quality Control | You want the AI to flag top issues, self-critique, and refine, minimizing manual QC steps. | WIRE+FRAME |
Prompting isn’t about getting it right the first time. It’s about designing the interaction and redesigning when needed. With WIRE+FRAME, you’re going beyond basic prompting and designing the interaction between you and AI.
From Gut Feel To Framework: A Prompt Makeover
Let’s compare the results of Kate’s first AI-augmented design sprint prompt (to synthesize customer feedback into design insights) with one based on the WIRE+FRAME prompt framework, with the same data and focusing on the top results:
Original prompt: Read this customer feedback and tell me how we can improve our app for Gen Z users.
Initial ChatGPT Results:
- Improve app reliability to reduce crashes and freezing.
- Provide better guidance or tutorials for financial tools like budgeting or goal setting.
- Enhance the transparency of Zelle transfers by showing confirmation messages.
- Speed up app loading and reduce lag on key actions.
With this version, you’d likely need to go back and forth with follow-up questions, rewrite the output for clarity, and add structure before sharing with your team.
WIRE+FRAME prompt above (with defined role, scope, rules, expected format, tone, flow, and evaluation loop).
Initial ChatGPT Results:
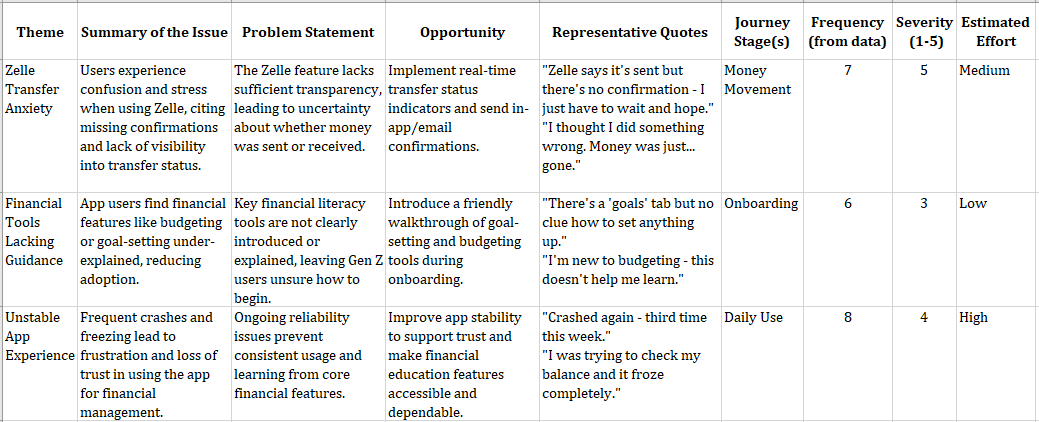{kind=link}
You can clearly see the very different results from the two prompts, both using the exact same data. While the first prompt returns a quick list of ideas, the detailed WIRE+FRAME version doesn’t just summarize feedback but structures it. Themes are clearly labeled, supported by user quotes, mapped to customer journey stages, and prioritized by frequency, severity, and effort.
The structured prompt results can be used as-is or shared without needing to reformat, rewrite, or explain them (see disclaimer below). The first prompt output needs massaging: it’s not detailed, lacks evidence, and would require several rounds of clarification to be actionable. The first prompt may work when the stakes are low and you are exploring. But when your prompt is feeding design, product, or strategy, structure comes to the rescue.
Disclaimer: Know Your Data
A well-structured prompt can make AI output more useful, but it shouldn’t be the final word, or your single source of truth. AI models are powerful pattern predictors, not fact-checkers. If your data is unclear or poorly referenced, even the best prompt may return confident nonsense. Don’t blindly trust what you see. Treat AI like a bright intern: fast, eager, and occasionally delusional. You should always be familiar with your data and validate what AI spits out. For example, in the WIRE+FRAME results above, AI rated the effort as low for financial tool onboarding. That could easily be a medium or high. Good prompting should be backed by good judgment.
Try This Now
Start by using the WIRE+FRAME framework to create a prompt that will help AI augment your work. You could also rewrite the last prompt you were not satisfied with, using the WIRE+FRAME, and compare the output.
Feel free to use this simple tool to guide you through the framework.
Methods: From Lone Prompts to a Prompt System
Just as design systems have reusable components, your prompts can too. You can use the WIRE+FRAME framework to write detailed prompts, but you can also use the structure to create reusable components that are pre-tested, plug-and-play pieces you can assemble to build high-quality prompts faster. Each part of WIRE+FRAME can be transformed into a prompt component: small, reusable modules that reflect your team’s standards, voice, and strategy.
For instance, if you find yourself repeatedly using the same content for different parts of the WIRE+FRAME framework, you could save them as reusable components for you and your team. In the example below, we have two different reusable components for “W: Who & What” — an insights analyst and an information architect.
W: Who & What
- You are a senior UX researcher and customer insights analyst. You specialize in synthesizing qualitative data from diverse sources to identify patterns, surface user pain points, and map them across customer journey stages. Your outputs directly inform product, UX, and service priorities.
- You are an experienced information architect specializing in organizing enterprise content on intranets. Your task is to reorganize the content and features into categories that reflect user goals, reduce cognitive load, and increase findability.
Create and save prompt components and variations for each part of the WIRE+FRAME framework, allowing your team to quickly assemble new prompts by combining components when available, rather than starting from scratch each time.
Behind The Prompts: Questions About Prompting
Q: If I use a prompt framework like WIRE+FRAME every time, will the results be predictable?
A: Yes and no. Yes, your outputs will be guided by a consistent set of instructions (e.g., Rules, Examples, Reference Voice / Style) that will guide the AI to give you a predictable format and style of results. And no, while the framework provides structure, it doesn’t flatten the generative nature of AI, but focuses it on what’s important to you. In the next article, we will look at how you can use this to your advantage to quickly reuse your best repeatable prompts as we build your AI assistant.
Q: Could changes to AI models break the WIRE+FRAME framework?
A: AI models are evolving more rapidly than any other technology we’ve seen before — in fact, ChatGPT was recently updated to GPT-5 to mixed reviews. The update didn’t change the core principles of prompting or the WIRE+FRAME prompt framework. With future releases, some elements of how we write prompts today may change, but the need to communicate clearly with AI won’t. Think of how you delegate work to an intern vs. someone with a few years’ experience: you still need detailed instructions the first time either is doing a task, but the level of detail may change. WIRE+FRAME isn’t built only for today’s models; the components help you clarify your intent, share relevant context, define constraints, and guide tone and format — all timeless elements, no matter how smart the model becomes. The skill of shaping clear, structured interactions with non-human AI systems will remain valuable.
Q: Can prompts be more than text? What about images or sketches?
A: Absolutely. With tools like GPT-5 and other multimodal models, you can upload screenshots, pictures, whiteboard sketches, or wireframes. These visuals become part of your Input Context or help define the Expected Output. The same WIRE+FRAME principles still apply: you’re setting context, tone, and format, just using images and text together. Whether your input is a paragraph or an image and text, you’re still designing the interaction.
Have a prompt-related question of your own? Share it in the comments, and I’ll either respond there or explore it further in the next article in this series.
From Designerly Prompting To Custom Assistants
Good prompts and results don’t come from using others’ prompts, but from writing prompts that are customized for you and your context. The WIRE+FRAME framework helps with that and makes prompting a tool you can use to guide AI models like a creative partner instead of hoping for magic from a one-line request.
Prompting uses the designerly skills you already use every day to collaborate with AI:
- Curiosity to explore what the AI can do and frame better prompts.
- Observation to detect bias or blind spots.
- Empathy to make machine outputs human.
- Critical thinking to verify and refine.
- Experiment & Iteration to learn by doing and improve the interaction over time.
- Growth Mindset to keep up with new technology like AI and prompting.
Once you create and refine prompt components and prompts that work for you, make them reusable by documenting them. But wait, there’s more — what if your best prompts, or the elements of your prompts, could live inside your own AI assistant, available on demand, fluent in your voice, and trained on your context? That’s where we’re headed next.
In the next article, “Design Your Own Design Assistant”, we’ll take what you’ve learned so far and turn it into a Custom AI assistant (aka Custom GPT), a design-savvy, context-aware assistant that works like you do. We’ll walk through that exact build, from defining the assistant’s job description to uploading knowledge, testing, and sharing it with others.
Resources
- GPT-5 Prompting Guide
- GPT-4.1 Prompting Guide
- Anthropic Prompt Engineering
- Prompt Engineering by Google
- Perplexity
- Webapp to guide you through the WIRE+FRAME framework
(yk)

Designing For TV: The Evergreen Pattern That Shapes TV Experiences
Designing For TV: The Evergreen Pattern That Shapes TV Experiences Designing For TV: The Evergreen Pattern That Shapes TV Experiences Milan Balać 2025-08-27T13:00:00+00:00 2025-08-27T15:32:36+00:00 Television sets have been the staple of our living rooms for decades. We watch, we interact, and we control, but how […]
Accessibility
Designing For TV: The Evergreen Pattern That Shapes TV Experiences
Milan Balać 2025-08-27T13:00:00+00:00
2025-08-27T15:32:36+00:00
Television sets have been the staple of our living rooms for decades. We watch, we interact, and we control, but how often do we design for them? TV design flew under my “radar” for years, until one day I found myself in the deep, designing TV-specific user interfaces. Now, after gathering quite a bit of experience in the area, I would like to share my knowledge on this rather rare topic. If you’re interested in learning more about the user experience and user interfaces of television, this article should be a good starting point.
Just like any other device or use case, TV has its quirks, specifics, and guiding principles. Before getting started, it will be beneficial to understand the core ins and outs. In Part 1, we’ll start with a bit of history, take a close look at the fundamentals, and review the evolution of television. In Part 2, we’ll dive into the depths of practical aspects of designing for TV, including its key principles and patterns.
Let’s start with the two key paradigms that dictate the process of designing TV interfaces.
Mind The Gap, Or The 10-foot-experience
Firstly, we have the so-called “10-foot experience,” referring to the fact that interaction and consumption on TV happens from a distance of roughly three or more meters. This is significantly different than interacting with a phone or a computer and implies having some specific approaches in the TV user interface design. For example, we’ll need to make text and user interface (UI) elements larger on TV to account for the bigger distance to the screen.
Furthermore, we’ll take extra care to adhere to contrast standards, primarily relying on dark interfaces, as light ones may be too blinding in darker surroundings. And finally, considering the laid-back nature of the device, we’ll simplify the interactions.
{kind=link}

But the 10-foot experience is only one part of the equation. There wouldn’t be a “10-foot experience” in the first place if there were no mediator between the user and the device, and if we didn’t have something to interact through from a distance.
There would be no 10-foot experience if there were no remote controllers.
The Mediator
The remote, the second half of the equation, is what allows us to interact with the TV from the comfort of the couch. Slower and more deliberate, this conglomerate of buttons lacks the fluid motion of a mouse, or the dexterity of fingers against a touchscreen — yet the capabilities of the remote should not be underestimated.
Rudimentary as it is and with a limited set of functions, the remote allows for some interesting design approaches and can carry the weight of the modern TV along with its ever-growing requirements for interactivity. It underwent a handful of overhauls during the seventy years since its inception and was refined and made more ergonomic; however, there is a 40-year-old pattern so deeply ingrained in its foundation that nothing can change it.
What if I told you that you could navigate TV interfaces and apps with a basic controller from the 1980s just as well as with the latest remote from Apple? Not only that, but any experience built around the six core buttons of a remote will be system-agnostic and will easily translate across platforms.
This is the main point I will focus on for the rest of this article.
Birth Of A Pattern
As television sets were taking over people’s living rooms in the 1950s, manufacturers sought to upgrade and improve the user experience. The effort of walking up to the device to manually adjust some settings was eventually identified as an area for improvement, and as a result, the first television remote controllers were introduced to the market.
Early Developments
Preliminary iterations of the remotes were rather unique, and it took some divergence before we finally settled on a rectangular shape and sprinkled buttons on top.
Take a look at the Zenith Flash-Matic, for example. Designed in the mid-1950s, this standout device featured a single button that triggered a directional lamp; by pointing it at specific corners of the TV set, viewers could control various functions, such as changing channels or adjusting the volume.
{kind=link}

While they were a far cry compared to their modern counterparts, devices like the Flash-Matic set the scene for further developments, and we were off to the races!
As the designs evolved, the core functionality of the remote solidified. Gradually, remote controls became more than just simple channel changers, evolving into command centers for the expanding territory of home entertainment.
Note: I will not go too much into history here — aside from some specific points that are of importance to the matter at hand — but if you have some time to spare, do look into the developmental history of television sets and remotes, it’s quite a fascinating topic.
{kind=link}

However, practical as they may have been, they were still considered a luxury, significantly increasing the prices of TV sets. As the 1970s were coming to a close, only around 17% of United States households had a remote controller for their TVs. Yet, things would change as the new decade rolled in.
Button Mania Of The 1980s
The eighties brought with them the Apple Macintosh, MTV, and Star Wars. It was a time of cultural shifts and technological innovation. Videocassette recorders (VCRs) and a multitude of other consumer electronics found their place in the living rooms of the world, along with TVs.
These new devices, while enriching our media experiences, also introduced a few new design problems. Where there was once a single remote, now there were multiple remotes, and things were getting slowly out of hand.
This marked the advent of universal remotes.
{kind=link}

Trying to hit many targets with one stone, the unwieldy universal remotes were humanity’s best solution for controlling a wider array of devices. And they did solve some of these problems, albeit in an awkward way. The complexity of universal remotes was a trade-off for versatility, allowing them to be programmed and used as a command center for controlling multiple devices. This meant transforming the relatively simple design of their predecessors into a beehive of buttons, prioritizing broader compatibility over elegance.
On the other hand, almost as a response to the inconvenience of the universal remote, a different type of controller was conceived in the 1980s — one with a very basic layout and set of buttons, and which would leave its mark in both how we interact with the TV, and how our remotes are laid out. A device that would, knowingly or not, give birth to a navigational pattern that is yet to be broken — the NES controller.
D-pad Dominance
Released in 1985, the Nintendo Entertainment System (NES) was an instant hit. Having sold sixty million units around the world, it left an undeniable mark on the gaming console industry.
{kind=link}

{kind=link}
The NES controller (which was not truly remote, as it ran a cable to the central unit) introduced the world to a deceptively simple control scheme. Consisting of six primary actions, it gave us the directional pad (the D-pad), along with two action buttons (A and B). Made in response to the bulky joystick, the cross-shaped cluster allowed for easy movement along two axes (up, down, left, and right).
Charmingly intuitive, this navigational pattern would produce countless hours of gaming fun, but more importantly, its elementary design would “seep over” into the wider industry — the D-pad, along with the two action buttons, would become the very basis on which future remotes would be constructed.
The world continued spinning madly on, and what was once a luxury became commonplace. By the end of the decade, TV remotes were more integral to the standard television experience, and more than two-thirds of American TV owners had some sort of a remote.
The nineties rolled in with further technological advancements. TV sets became more robust, allowing for finer tuning of their settings. This meant creating interfaces through which such tasks could be accomplished, and along with their master sets, remotes got updated as well.
Gone were the bulky rectangular behemoths of the eighties. As ergonomics took precedence, they got replaced by comfortably contoured devices that better fit their users’ hands. Once conglomerations of dozens of uniform buttons, these contemporary remotes introduced different shapes and sizes, allowing for recognition simply through touch. Commands were being clustered into sensible groups along the body of the remote, and within those button groups, a familiar shape started to emerge.
{kind=link}

Gradually, the D-pad found its spot on our TV remotes. As the evolution of these devices progressed, it became even more deeply embedded at the core of their interactivity.
{kind=link}

Set-top boxes and smart features emerged in the 2000s and 2010s, and TV technology continued to advance. Along the way, many bells and whistles were introduced. TVs got bigger, brighter, thinner, yet their essence remained unchanged.
In the years since their inception, remotes were innovated upon, but all the undertakings circle back to the core principles of the NES controller. Future endeavours never managed to replace, but only to augment and reinforce the pattern.
The Evergreen Pattern
In 2013, LG introduced their Magic remote (“So magically simple, the kids will be showing you how to use it!”). This uniquely shaped device enabled motion controls on LG TV sets, allowing users to point and click similar to a computer mouse. Having a pointer on the screen allowed for much more flexibility and speed within the system, and the remote was well-received and praised as one of the best smart TV remotes.
{kind=link}

Innovating on tradition, this device introduced new features and fresh perspectives to the world of TV. But if we look at the device itself, we’ll see that, despite its differences, it still retains the D-pad as a means of interaction. It may be argued that LG never set out to replace the directional pad, and as it stands, regardless of their intent, they only managed to augment it.
For an even better example, let’s examine Apple TV’s second-generation remotes (the first-generation Siri remote). Being the industry disruptors, Apple introduced a touchpad to the top half of the remote. The glass surface provided briskness and precision to the experience, enabling multi-touch gestures, swipe navigation, and quick scrolling. This quality of life upgrade was most noticeable when typing with the horizontal on-screen keyboards, as it allowed for smoother and quicker scrolling from A to Z, making for a more refined experience.
{kind=link}

While at first glance it may seem Apple removed the directional buttons, the fact is that the touchpad is simply a modernised take on the pattern, still abiding by the same four directions a classic D-pad does. You could say it’s a D-pad with an extra layer of gimmick.
Furthermore, the touchpad didn’t really sit well with the user base, along with the fact that the remote’s ergonomics were a bit iffy. So instead of pushing the boundaries even further with their third generation of remotes, Apple did a complete 180, re-introducing the classic D-pad cluster while keeping the touch capabilities from the previous generation (the touch-enabled clickpad lets you select titles, swipe through playlists, and use a circular gesture on the outer ring to find just the scene you’re looking for).
{kind=link}

Now, why can’t we figure out a better way to navigate TVs? Does that mean we shouldn’t try to innovate?
We can argue that using motion controls and gestures is an obvious upgrade to interacting with a TV. And we’d be right… in principle. These added features are more complex and costly to produce, but more importantly, while it has been upgraded with bits and bobs, the TV is essentially a legacy system. And it’s not only that.
While touch controls are a staple of interaction these days, adding them without thorough consideration can reduce the usability of a remote.
“
Pitfalls Of Touch Controls
Modern car dashboards are increasingly being dominated by touchscreens. While they may impress at auto shows, their real-world usability is often compromised.
Driving demands constant focus and the ability to adapt and respond to ever-changing conditions. Any interface that requires taking your eyes off the road for more than a moment increases the risk of accidents. That’s exactly where touch controls fall short. While they may be more practical (and likely cheaper) for manufacturers to implement, they’re often the opposite for the end user.
Unlike physical buttons, knobs, and levers, which offer tactile landmarks and feedback, touch interfaces lack the ability to be used by feeling alone. Even simple tasks like adjusting the volume of the radio or the climate controls often involve gestures and nested menus, all performed on a smooth glass surface that demands visual attention, especially when fine-tuning.
Fortunately, the upcoming 2026 Euro NCAP regulations will encourage car manufacturers to reintroduce physical controls for core functions, reducing driver distraction and promoting safer interaction.
Similarly (though far less critically), sleek, buttonless TV remote controls may feel modern, but they introduce unnecessary abstraction to a familiar set of controls.
Physical buttons with distinct shapes and positioning allow users to navigate by memory and touch, even in the dark. That’s not outdated — it’s a deeper layer of usability that modern design should respect, not discard.
“
And this is precisely why Apple reworked the Apple TV third-generation remote the way it is now, where the touch area at the top disappeared. Instead, the D-pad again had clearly defined buttons, and at the same time, the D-pad could also be extended (not replaced) to accept some touch gestures.
The Legacy Of TV
Let’s take a look at an old on-screen keyboard.
{kind=link}
The Legend of Zelda, released in 1986, allowed players to register their names in-game. There are even older games with the same feature, but that’s beside the point. Using the NES controller, the players would move around the keyboard, entering their moniker character by character. Now let’s take a look at a modern iteration of the on-screen keyboard.
{kind=link}
Notice the difference? Or, to phrase it better: do you notice the similarities? Throughout the years, we’ve introduced quality of life improvements, but the core is exactly the same as it was forty years ago. And it is not the lack of innovation or bad remotes that keep TV deeply ingrained in its beginnings. It’s simply that it’s the most optimal way to interact given the circumstances.
Laying It All Out
Just like phones and computers, TV layouts are based on a grid system. However, this system is a lot more apparent and rudimentary on TV. Taking a look at a standard TV interface, we’ll see that it consists mainly of horizontal and vertical lists, also known as shelves.
{kind=link}
These grids may be populated with cards, characters of the alphabet, or anything else, essentially, and upon closer examination, we’ll notice that our movement is restricted by a few factors:
- There is no pointer for our eyes to follow, like there would be on a computer.
- There is no way to interact directly with the display like we would with a touchscreen.
For the purposes of navigating with a remote, a focus state is introduced. This means that an element will always be highlighted for our eyes to anchor, and it will be the starting point for any subsequent movement within the interface.

Moreover, starting from the focused element, we can notice that the movement is restricted to one item at a time, almost like skipping stones. Navigating linearly in such a manner, if we wanted to move within a list of elements from element #1 to element #5, we’d have to press a directional button four times.

To successfully navigate such an interface, we need the ability to move left, right, up, and down — we need a D-pad. And once we’ve landed on our desired item, there needs to be a way to select it or make a confirmation, and in the case of a mistake, we need to be able to go back. For the purposes of those two additional interactions, we’d need two more buttons, OK and back, or to make it more abstract, we’d need buttons A and B.
So, to successfully navigate a TV interface, we need only a NES controller.
Yes, we can enhance it with touchpads and motion gestures, augment it with voice controls, but this unshakeable foundation of interaction will remain as the very basic level of inherent complexity in a TV interface. Reducing it any further would significantly impair the experience, so all we’ve managed to do throughout the years is to only build upon it.
The D-pad and buttons A and B survived decades of innovation and technological shifts, and chances are they’ll survive many more. By understanding and respecting this principle, you can design intuitive, system-agnostic experiences and easily translate them across platforms. Knowing you can’t go simpler than these six buttons, you’ll easily build from the ground up and attach any additional framework-bound functionality to the time-tested core.
And once you get the grip of these paradigms, you’ll get into mapping and re-mapping buttons depending on context, and understand just how far you can go when designing for TV. You’ll be able to invent new experiences, conduct experiments, and challenge the patterns. But that is a topic for a different article.
Closing Thoughts
While designing for TV almost exclusively during the past few years, I was also often educating the stakeholders on the very principles outlined in this article. Trying to address their concerns about different remotes working slightly differently, I found respite in the simplicity of the NES controller and how it got the point across in an understandable way. Eventually, I expanded my knowledge by looking into the developmental history of the remote and was surprised that my analogy had backing in history. This is a fascinating niche, and there’s a lot more to share on the topic. I’m glad we started!
It’s vital to understand the fundamental “ins” and “outs” of any venture before getting practical, and TV is no different. Now that you understand the basics, go, dig in, and break some ground.
Having covered the underlying interaction patterns of TV experiences in detail, it’s time to get practical.
In Part 2, we’ll explore the building blocks of the 10-foot experience and how to best utilize them in your designs. We’ll review the TV design fundamentals (the screen, layout, typography, color, and focus/focus styles), and the common TV UI components (menus, “shelves,” spotlights, search, and more). I will also show you how to start thinking beyond the basics and to work with — and around — the constraints which we abide by when designing for TV. Stay tuned!
Further Reading
- “The 10 Foot Experience,” by Robert Stulle (Edenspiekermann)
Every user interface should offer effortless navigation and control. For the 10-foot experience, this is twice as important; with only up, down, left, right, OK and back as your input vocabulary, things had better be crystal clear. You want to sit back and enjoy without having to look at your remote — your thumb should fly over the buttons to navigate, select, and activate. - “Introduction to the 10-Foot Experience for Windows Game Developers” (Microsoft Learn)
A growing number of people are using their personal computers in a completely new way. When you think of typical interaction with a Windows-based computer, you probably envision sitting at a desk with a monitor, and using a mouse and keyboard (or perhaps a joystick device); this is referred to as the 2-foot experience. But there’s another trend which you’ll probably start hearing more about: the 10-foot experience, which describes using your computer as an entertainment device with output to a TV. This article introduces the 10-foot experience and explores the list of things that you should consider first about this new interaction pattern, even if you aren’t expecting your game to be played this way. - “10-foot user interface” (Wikipedia)
In computing, a 10-foot user interface, or 3-meter UI, is a graphical user interface designed for televisions (TV). Compared to desktop computer and smartphone user interfaces, it uses text and other interface elements that are much larger in order to accommodate a typical television viewing distance of 10 feet (3.0 meters); in reality, this distance varies greatly between households, and additionally, the limitations of a television’s remote control necessitate extra user experience considerations to minimize user effort. - “The Television Remote Control: A Brief History,” by Mary Bellis (ThoughtCo)
The first TV remote, the Lazy Bone, was made in 1950 and used a cable. In 1955, the Flash-matic was the first wireless remote, but it had issues with sunlight. Zenith’s Space Command in 1956 used ultrasound and became the popular choice for over 25 years. - “The History of The TV Remote,” by Remy Millisky (Grunge)
The first person to create and patent the remote control was none other than Nikola Tesla, inventor of the Tesla coil and numerous electronic systems. He patented the idea in 1893 to drive boats remotely, far before televisions were invented. Since then, remotes have come a long way, especially for the television, changing from small boxes with long wires to the wireless universal remotes that many people have today. How has the remote evolved over time? - “Nintendo Entertainment System controller” (Nintendo Wiki)
The Nintendo Entertainment System controller is the main controller for the NES. While previous systems had used joysticks, the NES controller provided a directional pad (the D-pad was introduced in the Game & Watch version of Donkey Kong). - “Why Touchscreens In Cars Don’t Work,” by Jacky Li (published in June 2018)
Observing the behaviour of 21 drivers has made me realize what’s wrong with automotive UX. […] While I was excited to learn more about the Tesla Model X, it slowly became apparent to me that the driver’s eyes were more glued to the screen than the road. Something about interacting with a touchscreen when driving made me curious to know: just how distracting are they? - “Europe Is Requiring Physical Buttons For Cars To Get Top Safety Marks,” by Jason Torchinsky (published in March 2024)
The overuse of touchscreens is an industry-wide problem, with almost every vehicle-maker moving key controls onto central touchscreens, obliging drivers to take their eyes off the road and raising the risk of distraction crashes. New Euro NCAP tests due in 2026 will encourage manufacturers to use separate, physical controls for basic functions in an intuitive manner, limiting eyes-off-road time and therefore promoting safer driving.
(mb, yk)
A Week In The Life Of An AI-Augmented Designer
A Week In The Life Of An AI-Augmented Designer A Week In The Life Of An AI-Augmented Designer Lyndon Cerejo 2025-08-22T08:00:00+00:00 2025-08-27T15:32:36+00:00 Artificial Intelligence isn’t new, but in November 2022, something changed. The launch of ChatGPT brought AI out of the background and into everyday […]
Accessibility
A Week In The Life Of An AI-Augmented Designer
Lyndon Cerejo 2025-08-22T08:00:00+00:00
2025-08-27T15:32:36+00:00
Artificial Intelligence isn’t new, but in November 2022, something changed. The launch of ChatGPT brought AI out of the background and into everyday life. Suddenly, interacting with a machine didn’t feel technical — it felt conversational.
Just this March, ChatGPT overtook Instagram and TikTok as the most downloaded app in the world. That level of adoption shows that millions of everyday users, not just developers or early adopters, are comfortable using AI in casual, conversational ways. People are using AI not just to get answers, but to think, create, plan, and even to help with mental health and loneliness.
In the past two and a half years, people have moved through the Kübler-Ross Change Curve — only instead of grief, it’s AI-induced uncertainty. UX designers, like Kate (who you’ll meet shortly), have experienced something like this:
- Denial: “AI can’t design like a human; it won’t affect my workflow.”
- Anger: “AI will ruin creativity. It’s a threat to our craft.”
- Bargaining: “Okay, maybe just for the boring tasks.”
- Depression: “I can’t keep up. What’s the future of my skills?”
- Acceptance: “Alright, AI can free me up for more strategic, human work.”
As designers move into experimentation, they’re not asking, Can I use AI? but How might I use it well?.
Using AI isn’t about chasing the latest shiny object but about learning how to stay human in a world of machines, and use AI not as a shortcut, but as a creative collaborator.
“
It isn’t about finding, bookmarking, downloading, or hoarding prompts, but experimenting and writing your own prompts.
To bring this to life, we’ll follow Kate, a mid-level designer at a FinTech company, navigating her first AI-augmented design sprint. You’ll see her ups and downs as she experiments with AI, tries to balance human-centered skills with AI tools, when she relies on intuition over automation, and how she reflects critically on the role of AI at each stage of the sprint.
The next two planned articles in this series will explore how to design prompts (Part 2) and guide you through building your own AI assistant (aka CustomGPT; Part 3). Along the way, we’ll spotlight the designerly skills AI can’t replicate like curiosity, empathy, critical thinking, and experimentation that will set you apart in a world where automation is easy, but people and human-centered design matter even more.
Note: This article was written by a human (with feelings, snacks, and deadlines). The prompts are real, the AI replies are straight from the source, and no language models were overworked — just politely bossed around. All em dashes are the handiwork of MS Word’s autocorrect — not AI. Kate is fictional, but her week is stitched together from real tools, real prompts, real design activities, and real challenges designers everywhere are navigating right now. She will primarily be using ChatGPT, reflecting the popularity of this jack-of-all-trades AI as the place many start their AI journeys before branching out. If you stick around to the end, you’ll find other AI tools that may be better suited for different design sprint activities. Due to the pace of AI advances, your outputs may vary (YOMV), possibly by the time you finish reading this sentence.
Cautionary Note: AI is helpful, but not always private or secure. Never share sensitive, confidential, or personal information with AI tools — even the helpful-sounding ones. When in doubt, treat it like a coworker who remembers everything and may not be particularly good at keeping secrets.
Prologue: Meet Kate (As She Preps For The Upcoming Week)
Kate stared at the digital mountain of feedback on her screen: transcripts, app reviews, survey snippets, all waiting to be synthesized. Deadlines loomed. Her calendar was a nightmare. Meanwhile, LinkedIn was ablaze with AI hot takes and success stories. Everyone seemed to have found their “AI groove” — except her. She wasn’t anti-AI. She just hadn’t figured out how it actually fit into her work. She had tried some of the prompts she saw online, played with some AI plugins and extensions, but it felt like an add-on, not a core part of her design workflow.
Her team was focusing on improving financial confidence for Gen Z users of their FinTech app, and Kate planned to use one of her favorite frameworks: the Design Sprint, a five-day, high-focus process that condenses months of product thinking into a single week. Each day tackles a distinct phase: Understand, Sketch, Decide, Prototype, and Test. All designed to move fast, make ideas tangible, and learn from real users before making big bets.
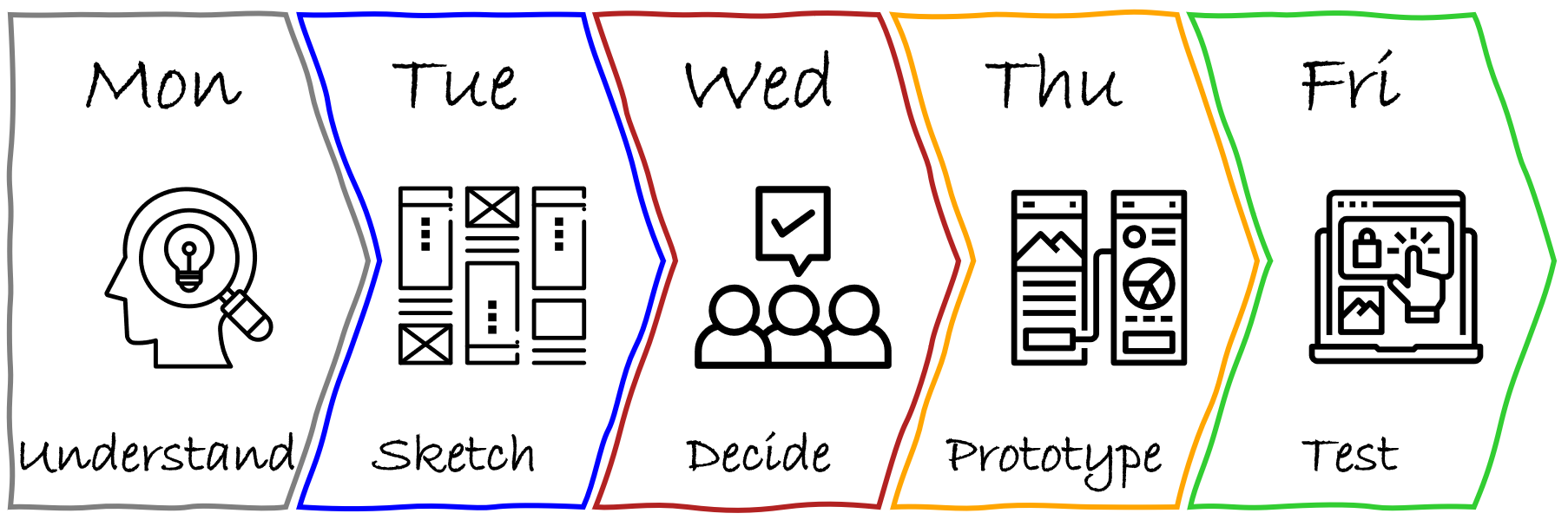{kind=link}
This time, she planned to experiment with a very lightweight version of the design sprint, almost “solo-ish” since her PM and engineer were available for check-ins and decisions, but not present every day. That gave her both space and a constraint, and made it the perfect opportunity to explore how AI could augment each phase of the sprint.
She decided to lean on her designerly behavior of experimentation and learning and integrate AI intentionally into her sprint prep, using it as both a creative partner and a thinking aid. Not with a rigid plan, but with a working hypothesis that AI would at the very least speed her up, if nothing else.
She wouldn’t just be designing and testing a prototype, but prototyping and testing what it means to design with AI, while still staying in the driver’s seat.
Follow Kate along her journey through her first AI-powered design sprint: from curiosity to friction and from skepticism to insight.
Monday: Understanding the Problem (aka: Kate Vs. Digital Pile Of Notes)
The first day of a design sprint is spent understanding the user, their problems, business priorities, and technical constraints, and narrowing down the problem to solve that week.
This morning, Kate had transcripts from recent user interviews and customer feedback from the past year from app stores, surveys, and their customer support center. Typically, she would set aside a few days to process everything, coming out with glazed eyes and a few new insights. This time, she decided to use ChatGPT to summarize that data: “Read this customer feedback and tell me how we can improve financial literacy for Gen Z in our app.”
ChatGPT’s outputs were underwhelming to say the least. Disappointed, she was about to give up when she remembered an infographic about good prompting that she had emailed herself. She updated her prompt based on those recommendations:
- Defined a role for the AI (“product strategist”),
- Provided context (user group and design sprint objectives), and
- Clearly outlined what she was looking for (financial literacy related patterns in pain points, blockers, confusion, lack of confidence; synthesis to identify top opportunity areas).
By the time she Aero-pressed her next cup of coffee, ChatGPT had completed its analysis, highlighting blockers like jargon, lack of control, fear of making the wrong choice, and need for blockchain wallets. Wait, what? That last one felt off.
{kind=link}

Kate searched her sources and confirmed her hunch: AI hallucination! Despite the best of prompts, AI sometimes makes things up based on trendy concepts from its training data rather than actual data. Kate updated her prompt with constraints to make ChatGPT only use data she had uploaded, and to cite examples from that data in its results. 18 seconds later, the updated results did not mention blockchain or other unexpected results.
By lunch, Kate had the makings of a research summary that would have taken much, much longer, and a whole lot of caffeine.
That afternoon, Kate and her product partner plotted the pain points on the Gen Z app journey. The emotional mapping highlighted the most critical moment: the first step of a financial decision, like setting a savings goal or choosing an investment option. That was when fear, confusion, and lack of confidence held people back.
AI synthesis combined with human insight helped them define the problem statement as: “How might we help Gen Z users confidently take their first financial action in our app, in a way that feels simple, safe, and puts them in control?”
Kate’s Reflection
As she wrapped up for the day, Kate jotted down her reflections on her first day as an AI-augmented designer:
There’s nothing like learning by doing. I’ve been reading about AI and tinkering around, but took the plunge today. Turns out AI is much more than a tool, but I wouldn’t call it a co-pilot. Yet. I think it’s like a sharp intern: it has a lot of information, is fast, eager to help, but it lacks context, needs supervision, and can surprise you. You have to give it clear instructions, double-check its work, and guide and supervise it. Oh, and maintain boundaries by not sharing anything I wouldn’t want others to know.
Today was about listening — to users, to patterns, to my own instincts. AI helped me sift through interviews fast, but I had to stay curious to catch what it missed. Some quotes felt too clean, like the edges had been smoothed over. That’s where observation and empathy kicked in. I had to ask myself: what’s underneath this summary?
Critical thinking was the designerly skill I had to exercise most today. It was tempting to take the AI’s synthesis at face value, but I had to push back by re-reading transcripts, questioning assumptions, and making sure I wasn’t outsourcing my judgment. Turns out, the thinking part still belongs to me.
Tuesday: Sketching (aka: Kate And The Sea of OKish Ideas)
Day 2 of a design sprint focuses on solutions, starting by remixing and improving existing ideas, followed by people sketching potential solutions.
Optimistic, yet cautious after her experience yesterday, Kate started thinking about ways she could use AI today, while brewing her first cup of coffee. By cup two, she was wondering if AI could be a creative teammate. Or a creative intern at least. She decided to ask AI for a list of relevant UX patterns across industries. Unlike yesterday’s complex analysis, Kate was asking for inspiration, not insight, which meant she could use a simpler prompt: “Give me 10 unique examples of how top-rated apps reduce decision anxiety for first-time users — from FinTech, health, learning, or ecommerce.”
She received her results in a few seconds, but there were only 6, not the 10 she asked for. She expanded her prompt for examples from a wider range of industries. While reviewing the AI examples, Kate realized that one had accessibility issues. To be fair, the results met Kate’s ask since she had not specified accessibility considerations. She then went pre-AI and brainstormed examples with her product partner, coming up with a few unique local examples.
Later that afternoon, Kate went full human during Crazy 8s by putting a marker to paper and sketching 8 ideas in 8 minutes to rapidly explore different directions. Wondering if AI could live up to its generative nature, she uploaded pictures of her top 3 sketches and prompted AI to act as “a product design strategist experienced in Gen Z behavior, digital UX, and behavioral science”, gave it context about the problem statement, stage in the design sprint, and explicitly asked AI the following:
- Analyze the 3 sketch concepts and identify core elements or features that resonated with the goal.
- Generate 5 new concept directions, each of which should:
- Address the original design sprint challenge.
- Reflect Gen Z design language, tone, and digital behaviors.
- Introduce a unique twist, remix, or conceptual inversion of the ideas in the sketches.
- For each concept, provide:
- Name (e.g., “Monopoly Mode,” “Smart Start”);
- 1–2 sentence concept summary;
- Key differentiator from the original sketches;
- Design tone and/or behavioral psychology technique used.
The results included ideas that Kate and her product partner hadn’t considered, including a progress bar that started at 20% (to build confidence), and a sports-like “stock bracket” for first-time investors.
{kind=link}
Not bad, thought Kate, as she cherry-picked elements, combined and built on these ideas in her next round of sketches. By the end of the day, they had a diverse set of sketched solutions — some original, some AI-augmented, but all exploring how to reduce fear, simplify choices, and build confidence for Gen Z users taking their first financial step. With five concept variations and a few rough storyboards, Kate was ready to start converging on day 3.
Kate’s Reflection
Today was creatively energizing yet a little overwhelming! I leaned hard on AI to act as a creative teammate. It delivered a few unexpected ideas and remixed my Crazy 8s into variations I never would’ve thought of!
It also reinforced the need to stay grounded in the human side of design. AI was fast — too fast, sometimes. It spit out polished-sounding ideas that sounded right, but I had to slow down, observe carefully, and ask: Does this feel right for our users? Would a first-time user feel safe or intimidated here?
Critical thinking helped me separate what mattered from what didn’t. Empathy pulled me back to what Gen Z users actually said, and kept their voices in mind as I sketched. Curiosity and experimentation were my fuel. I kept tweaking prompts, remixing inputs, and seeing how far I could stretch a concept before it broke. Visual communication helped translate fuzzy AI ideas into something I could react to — and more importantly, test.
Wednesday: Deciding (aka Kate Tries to Get AI to Pick a Side)
Design sprint teams spend Day 3 critiquing each of their potential solutions to shortlist those that have the best chance of achieving their long-term goal. The winning scenes from the sketches are then woven into a prototype storyboard.
Design sprint Wednesdays were Kate’s least favorite day. After all the generative energy during Sketching Tuesday, today, she would have to decide on one clear solution to prototype and test. She was unsure if AI would be much help with judging tradeoffs or narrowing down options, and it wouldn’t be able to critique like a team. Or could it?
Kate reviewed each of the five concepts, noting strengths, open questions, and potential risks. Curious about how AI would respond, she uploaded images of three different design concepts and prompted ChatGPT for strengths and weaknesses. AI’s critique was helpful in summarizing the pros and cons of different concepts, including a few points she had not considered — like potential privacy concerns.
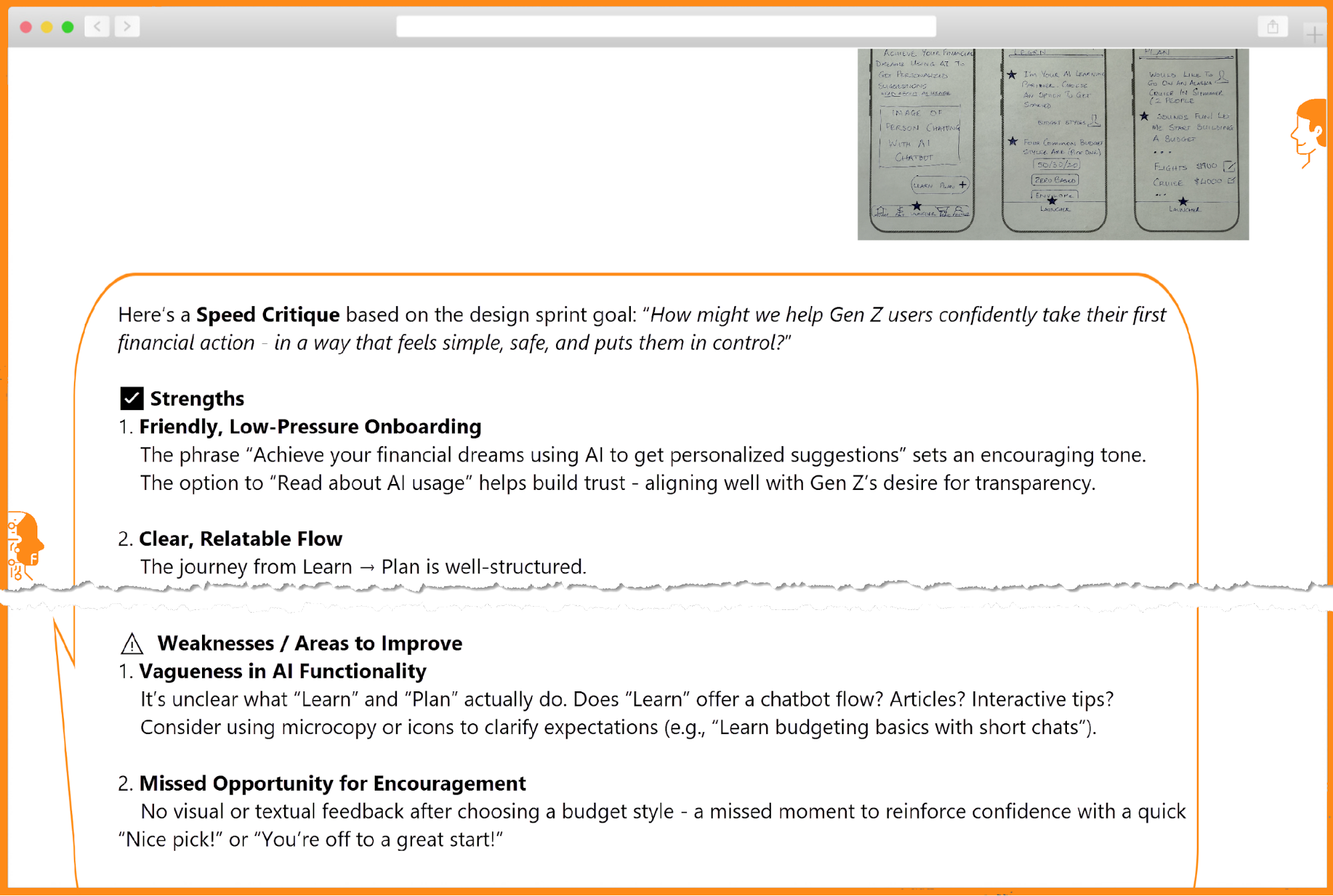{kind=link}

She asked a few follow-up questions to confirm the actual reasoning. Wondering if she could simulate a team critique by prompting ChatGPT differently, Kate asked it to use the 6 thinking hats technique. The results came back dense, overwhelming, and unfocused. The AI couldn’t prioritize, and it couldn’t see the gaps Kate instinctively noticed: friction in onboarding, misaligned tone, unclear next steps.
In that moment, the promise of AI felt overhyped. Kate stood up, stretched, and seriously considered ending her experiments with the AI-driven process. But she paused. Maybe the problem wasn’t the tool. Maybe it was how she was using it. She made a note to experiment when she wasn’t on a design sprint clock.
She returned to her sketches, this time laying them out on the wall. No screens, no prompts. Just markers, sticky notes, and Sharpie scribbles. Human judgment took over. Kate worked with her product partner to finalize the solution to test on Friday and spent the next hour storyboarding the experience in Figma.
Kate re-engaged with AI as a reviewer, not a decider. She prompted it for feedback on the storyboard and was surprised to see it spit out detailed design, content, and micro-interaction suggestions for each of the steps of the storyboarded experience. A lot of food for thought, but she’d have to judge what mattered when she created her prototype. But that wasn’t until tomorrow!
Kate’s Reflection
AI exposed a few of my blind spots in the critique, which was good, but it basically pointed out that multiple options “could work”. I had to rely on my critical thinking and instincts to weigh options logically, emotionally, and contextually in order to choose a direction that was the most testable and aligned with the user feedback from Day 1.
I was also surprised by the suggestions it came up with while reviewing my final storyboard, but I will need a fresh pair of eyes and all the human judgement I can muster tomorrow.
Empathy helped me walk through the flow like I was a new user. Visual communication helped pull it all together by turning abstract steps into a real storyboard for the team to see instead of imagining.
TO DO: Experiment prompting around the 6 Thinking Hats for different perspectives.
Thursday: Prototype (aka Kate And Faking It)
On Day 4, the team usually turns the storyboard from the previous day into a prototype that can be tested with users on Day 5. The prototype doesn’t need to be fully functional; a simulated experience is sufficient to gather user feedback.
Kate’s prototype day often consisted of marathon Figma Design sessions and late-night pizza dinners. She was hoping AI would change that today. She fed yesterday’s storyboard to ChatGPT and asked it for screens. It took a while to generate, but she was excited to see a screen flow gradually appear on her screen, except that it had 3 ¾ screens, instead of the 6 frames from her storyboard, as you can see in the image below.
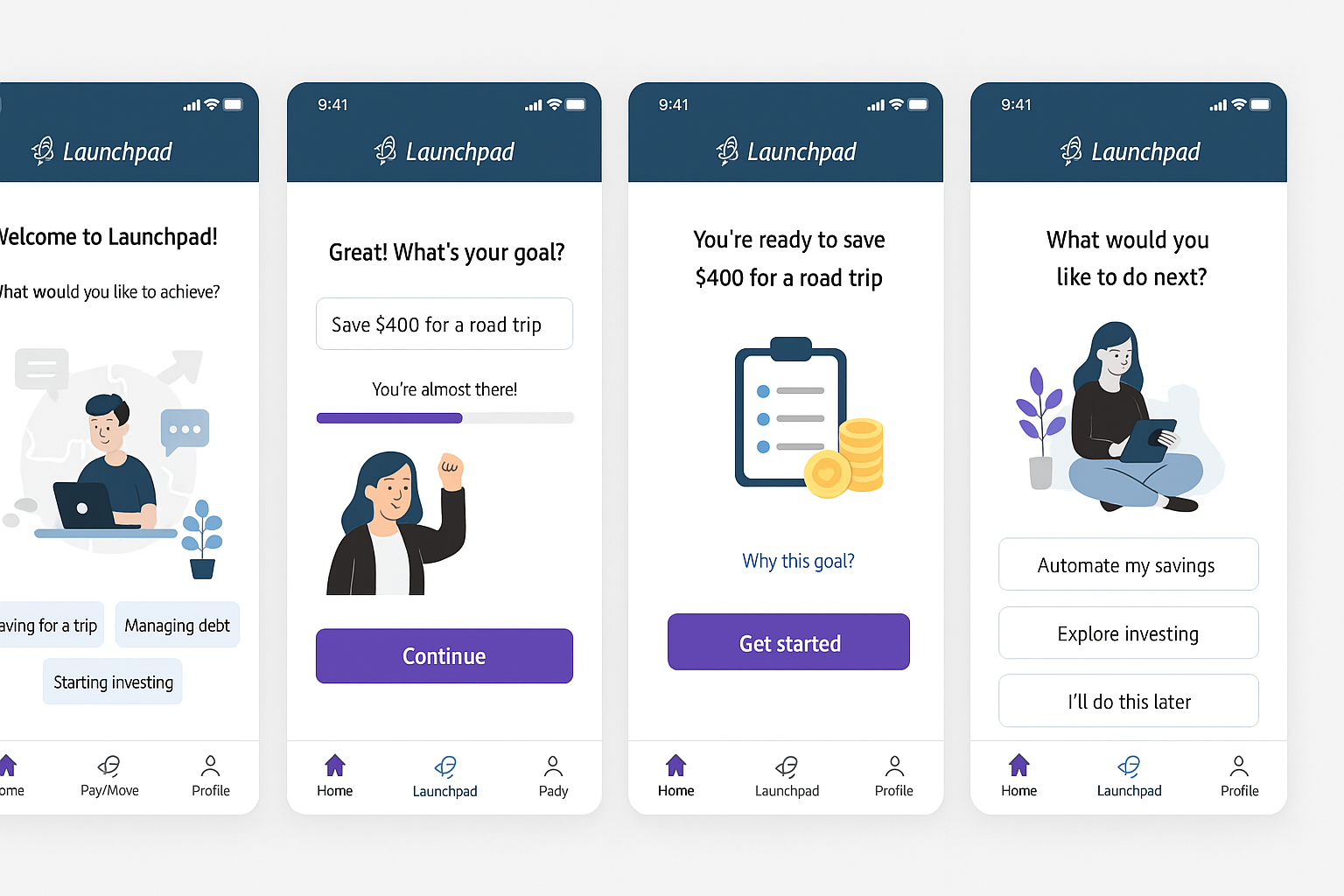{kind=link}
She tried different prompts but couldn’t get a complete flow. She was excited when it offered to create a Figma file. She waited. And waited. And reminded it that she was right there waiting. It finally gave her a link — a link that didn’t work. That made her question why she needed prototype screens in Figma at all. Could one of those no-code tools do the job? Kate remembered that she had just received beta access to Figma Make (Figma’s AI prompt-to-prototype tool) and decided to put it to the test.
She shared her storyboard, added context about the prototype for a design sprint, the problem, and a brief description of the audience. In a few seconds, she saw code being generated and a running description on the left. It seemed like it would take some time, so she headed to the cafeteria for lunch.
{kind=link}
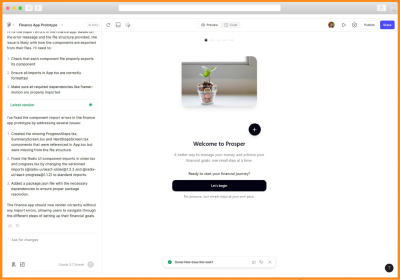
When Kate returned, she was surprised to see Figma Make had created an app along with a detailed explanation:
“I’ve created a complete finance app prototype with five key screens that guide users through setting financial goals in a friendly, low-pressure way. The app features smooth animations with Framer Motion, a progress indicator to show users where they are in the journey, and emotionally supportive visuals and copy throughout the experience. Each screen serves a specific purpose: welcoming users, helping them define relatable goals, building their plan with visual feedback, presenting a simple summary, and offering next steps without pressure.
You might want to:
- Add personalization options like user profiles or avatars.
- Implement a dark mode toggle for accessibility.
- Create additional goal templates and saving strategies.”
Since Figma Make had built the prototype, not her, Kate felt like she was User 0, and clicked her way through the interactive prototype, making a mental note of what worked, what didn’t. She was impressed to see that she could not only select a common goal (buy a home, save for education, and so on) but she could also create her own goal (hello De’Longhi Coffee Maker) and it carried over for the rest of the experience. This was something she had never been able to do in Figma Design!
Despite some obvious misses like a missing header and navigation, and some buttons not working, she was impressed! Kate tried the option to ‘Publish’ and it gave her a link that she immediately shared with her product and engineering partners. A few minutes later, they joined her in the conference room, exploring it together. The engineer scanned the code, didn’t seem impressed, but said it would work as a disposable prototype.
Kate prompted Figma Make to add an orange header and app navigation, and this time the trio kept their eyes peeled as they saw the progress in code and in English. The results were pretty good. They spent the next hour making changes to get it ready for testing. Even though he didn’t admit it, the engineer seemed impressed with the result, if not the code.
{kind=link}
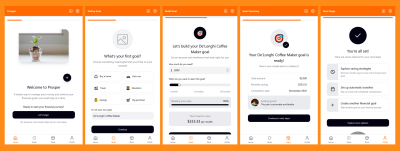
By late afternoon, they had a functioning interactive prototype. Kate fed ChatGPT the prototype link and asked it to create a usability testing script. It came up with a basic, but complete test script, including a checklist for observers to take notes.
{kind=link}
Kate went through the script carefully and updated it to add probing questions about AI transparency, emotional check-ins, more specific task scenarios, and a post-test debrief that looped back to the sprint goal.
Kate did a dry run with her product partner, who teased her: “Did you really need me? Couldn’t your AI do it?” It hadn’t occurred to her, but she was now curious!
“Act as a Gen Z user seeing this interactive prototype for the first time. How would you react to the language, steps, and tone? What would make you feel more confident or in control?”
It worked! ChatGPT simulated user feedback for the first screen and asked if she wanted it to continue. “Yes, please,” she typed. A few seconds later, she was reading what could have very well been a screen-by-screen transcript from a test.
{kind=link}

Kate was still processing what she had seen as she drove home, happy she didn’t have to stay late. The simulated test using AI appeared impressive at first glance. But the more she thought about it, the more disturbing it became. The output didn’t mention what the simulated user clicked, and if she had asked, she probably would have received an answer. But how useful would that be? After almost missing her exit, she forced herself to think about eating a relaxed meal at home instead of her usual Prototype-Thursday-Multitasking-Pizza-Dinner.
Kate’s Reflection
Today was the most meta I’ve felt all week: building a prototype about AI, with AI, while being coached by AI. And it didn’t all go the way I expected.
While ChatGPT didn’t deliver prototype screens, Figma Make coded a working, interactive prototype with interactions I couldn’t have built in Figma Design. I used curiosity and experimentation today, by asking: What if I reworded this? What if I flipped that flow?
AI moved fast, but I had to keep steering. But I have to admit that tweaking the prototype by changing the words, not code, felt like magic!
Critical thinking isn’t optional anymore — it is table stakes.
My impromptu ask of ChatGPT to simulate a Gen Z user testing my flow? That part both impressed and unsettled me. I’m going to need time to process this. But that can wait until next week. Tomorrow, I test with 5 Gen Zs — real people.
Friday: Test (aka Prototype Meets User)
Day 5 in a design sprint is a culmination of the week’s work from understanding the problem, exploring solutions, choosing the best, and building a prototype. It’s when teams interview users and learn by watching them react to the prototype and seeing if it really matters to them.
As Kate prepped for the tests, she grounded herself in the sprint problem statement and the users: “How might we help Gen Z users confidently take their first financial action in our app — in a way that feels simple, safe, and puts them in control?”
She clicked through the prototype one last time — the link still worked! And just in case, she also had screenshots saved.
Kate moderated the five tests while her product and engineering partners observed. The prototype may have been AI-generated, but the reactions were human. She observed where people hesitated, what made them feel safe and in control. Based on the participant, she would pivot, go off-script, and ask clarifying questions, getting deeper insights.
After each session, she dropped the transcripts and their notes into ChatGPT, asking it to summarize that user’s feedback into pain points, positive signals, and any relevant quotes. At the end of the five rounds, Kate prompted them for recurring themes to use as input for their reflection and synthesis.
{kind=link}
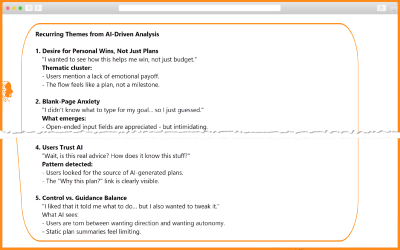
The trio combed through the results, with an eye out for any suspicious AI-generated results. They ran into one: “Users Trust AI”. Not one user mentioned or clicked the ‘Why this?’ link, but AI possibly assumed transparency features worked because they were available in the prototype.
They agreed that the prototype resonated with users, allowing all to easily set their financial goals, and identified a couple of opportunities for improvement: better explaining AI-generated plans and celebrating “win” moments after creating a plan. Both were fairly easy to address during their product build process.
That was a nice end to the week: another design sprint wrapped, and Kate’s first AI-augmented design sprint! She started Monday anxious about falling behind, overwhelmed by options. She closed Friday confident in a validated concept, grounded in real user needs, and empowered by tools she now knew how to steer.
Kate’s Reflection
Test driving my prototype with AI yesterday left me impressed and unsettled. But today’s tests with people reminded me why we test with real users, not proxies or people who interact with users, but actual end users. And GenAI is not the user. Five tests put my designerly skill of observation to the test.
GenAI helped summarize the test transcripts quickly but snuck in one last hallucination this week — about AI! With AI, don’t trust — always verify! Critical thinking is not going anywhere.
AI can move fast with words, but only people can use empathy to move beyond words to truly understand human emotions.
My next goal is to learn to talk to AI better, so I can get better results.
Conclusion
Over the course of five days, Kate explored how AI could fit into her UX work, not by reading articles or LinkedIn posts, but by doing. Through daily experiments, iterations, and missteps, she got comfortable with AI as a collaborator to support a design sprint. It accelerated every stage: synthesizing user feedback, generating divergent ideas, giving feedback, and even spinning up a working prototype, as shown below.
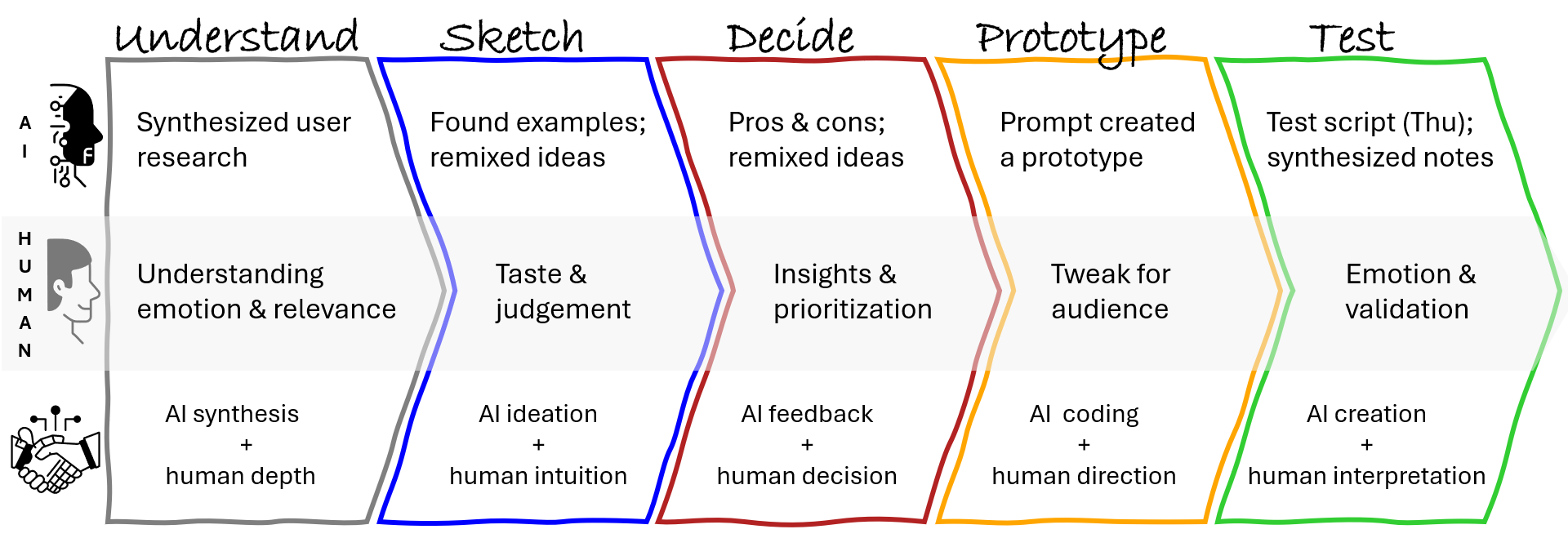{kind=link}
What was clear by Friday was that speed isn’t insight. While AI produced outputs fast, it was Kate’s designerly skills — curiosity, empathy, observation, visual communication, experimentation, and most importantly, critical thinking and a growth mindset — that turned data and patterns into meaningful insights. She stayed in the driver’s seat, verifying claims, adjusting prompts, and applying judgment where automation fell short.
She started the week on Monday, overwhelmed, her confidence dimmed by uncertainty and the noise of AI hype. She questioned her relevance in a rapidly shifting landscape. By Friday, she not only had a validated concept but had also reshaped her entire approach to design. She had evolved: from AI-curious to AI-confident, from reactive to proactive, from unsure to empowered. Her mindset had shifted: AI was no longer a threat or trend; it was like a smart intern she could direct, critique, and collaborate with. She didn’t just adapt to AI. She redefined what it meant to be a designer in the age of AI.
The experience raised deeper questions: How do we make sure AI-augmented outputs are not made up? How should we treat AI-generated user feedback? Where do ethics and human responsibility intersect?
Besides a validated solution to their design sprint problem, Kate had prototyped a new way of working as an AI-augmented designer.
The question now isn’t just “Should designers use AI?”. It’s “How do we work with AI responsibly, creatively, and consciously?”. That’s what the next article will explore: designing your interactions with AI using a repeatable framework.
Poll: If you could design your own AI assistant, what would it do?
- Assist with ideation?
- Research synthesis?
- Identify customer pain points?
- Or something else entirely?
Share your idea, and in the spirit of learning by doing, we’ll build one together from scratch in the third article of this series: Building your own CustomGPT.
Resources
- Sprint: How to Solve Big Problems and Test New Ideas in Just Five Days, by Jake Knapp
- The Design Sprint
- Figma Make
- “OpenAI Appeals ‘Sweeping, Unprecedented Order’ Requiring It Maintain All ChatGPT Logs”, Vanessa Taylor
Tools
As mentioned earlier, ChatGPT was the general-purpose LLM Kate leaned on, but you could swap it out for Claude, Gemini, Copilot, or other competitors and likely get similar results (or at least similarly weird surprises). Here are some alternate AI tools that might suit each sprint stage even better. Note that with dozens of new AI tools popping up every week, this list is far from exhaustive.
| Stage | Tools | Capability |
|---|---|---|
| Understand | Dovetail, UserTesting’s Insights Hub, Marvin | Summarize & Synthesize data |
| Sketch | Any LLM, Musely | Brainstorm concepts and ideas |
| Decide | Any LLM | Critique/provide feedback |
| Prototype | UIzard, UXPilot, Visily, Krisspy, Figma Make, Lovable, Bolt | Create wireframes and prototypes |
| Test | UserTesting, UserInterviews, PlaybookUX, Maze, plus tools from the Understand stage | Moderated and unmoderated user tests/synthesis |
(yk)
The Double-Edged Sustainability Sword Of AI In Web Design
The Double-Edged Sustainability Sword Of AI In Web Design The Double-Edged Sustainability Sword Of AI In Web Design Alex Williams 2025-08-20T10:00:00+00:00 2025-08-21T11:03:55+00:00 Artificial intelligence is increasingly automating large parts of design and development workflows — tasks once reserved for skilled designers and developers. This streamlining […]
Accessibility
The Double-Edged Sustainability Sword Of AI In Web Design
Alex Williams 2025-08-20T10:00:00+00:00
2025-08-21T11:03:55+00:00
Artificial intelligence is increasingly automating large parts of design and development workflows — tasks once reserved for skilled designers and developers. This streamlining can dramatically speed up project delivery. Even back in 2023, AI-assisted developers were found to complete tasks twice as fast as those without. And AI tools have advanced massively since then.
Yet this surge in capability raises a pressing dilemma:
Does the environmental toll of powering AI infrastructure eclipse the efficiency gains?
We can create websites faster that are optimized and more efficient to run, but the global consumption of energy by AI continues to climb.
As awareness grows around the digital sector’s hidden ecological footprint, web designers and businesses must grapple with this double-edged sword, weighing the grid-level impacts of AI against the cleaner, leaner code it can produce.
The Good: How AI Can Enhance Sustainability In Web Design
There’s no disputing that AI-driven automation has introduced higher speeds and efficiencies to many of the mundane aspects of web design. Tools that automatically generate responsive layouts, optimize image sizes, and refactor bloated scripts should free designers to focus on completing the creative side of design and development.
By some interpretations, these accelerated project timelines could represent a reduction in the required energy for development, and speedier production should mean less energy used.
Beyond automation, AI excels at identifying inefficiencies in code and design, as it can take a much more holistic view and assess things as a whole. Advanced algorithms can parse through stylesheets and JavaScript files to detect unused selectors or redundant logic, producing leaner, faster-loading pages. For example, AI-driven caching can increase cache hit rates by 15% by improving data availability and reducing latency. This means more user requests are served directly from the cache, reducing the need for data retrieval from the main server, which reduces energy expenditure.
AI tools can utilize next-generation image formats like AVIF or WebP, as they’re basically designed to be understood by AI and automation, and selectively compress assets based on content sensitivity. This slashes media payloads without perceptible quality loss, as the AI can use Generative Adversarial Networks (GANs) that can learn compact representations of data.
AI’s impact also brings sustainability benefits via user experience (UX). AI-driven personalization engines can dynamically serve only the content a visitor needs, which eliminates superfluous scripts or images that they don’t care about. This not only enhances perceived performance but reduces the number of server requests and data transferred, cutting downstream energy use in network infrastructure.
With the right prompts, generative AI can be an accessibility tool and ensure sites meet inclusive design standards by checking against accessibility standards, reducing the need for redesigns that can be costly in terms of time, money, and energy.
So, if you can take things in isolation, AI can and already acts as an important tool to make web design more efficient and sustainable. But do these gains outweigh the cost of the resources required in building and maintaining these tools?
The Bad: The Environmental Footprint Of AI Infrastructure
Yet the carbon savings engineered at the page level must be balanced against the prodigious resource demands of AI infrastructure. Large-scale AI hinges on data centers that already account for roughly 2% of global electricity consumption, a figure projected to swell as AI workloads grow.
The International Energy Agency warns that electricity consumption from data centers could more than double by 2030 due to the increasing demand for AI tools, reaching nearly the current consumption of Japan. Training state-of-the-art language models generates carbon emissions on par with hundreds of transatlantic flights, and inference workloads, serving billions of requests daily, can rival or exceed training emissions over a model’s lifetime.
Image generation tasks represent an even steeper energy hill to climb. Producing a single AI-generated image can consume energy equivalent to charging a smartphone.
As generative design and AI-based prototyping become more common in web development, the cumulative energy footprint of these operations can quickly undermine the carbon savings achieved through optimized code.
“
Water consumption forms another hidden cost. Data centers rely heavily on evaporative cooling systems that can draw between one and five million gallons of water per day, depending on size and location, placing stress on local supplies, especially in drought-prone regions. Studies estimate a single ChatGPT query may consume up to half a liter of water when accounting for direct cooling requirements, with broader AI use potentially demanding billions of liters annually by 2027.
Resource depletion and electronic waste are further concerns. High-performance components underpinning AI services, like GPUs, can have very small lifespans due to both wear and tear and being superseded by more powerful hardware. AI alone could add between 1.2 and 5 million metric tons of e-waste by 2030, due to the continuous demand for new hardware, amplifying one of the world’s fastest-growing waste streams.
Mining for the critical minerals in these devices often proceeds under unsustainable conditions due to a lack of regulations in many of the environments where rare metals can be sourced, and the resulting e-waste, rich in toxic metals like lead and mercury, poses another form of environmental damage if not properly recycled.
Compounding these physical impacts is a lack of transparency in corporate reporting. Energy and water consumption figures for AI workloads are often aggregated under general data center operations, which obscures the specific toll of AI training and inference among other operations.
And the energy consumption reporting of the data centres themselves has been found to have been obfuscated.
Reports estimate that the emissions of data centers are up to 662% higher than initially reported due to misaligned metrics, and ‘creative’ interpretations of what constitutes an emission. This makes it hard to grasp the true scale of AI’s environmental footprint, leaving designers and decision-makers unable to make informed, environmentally conscious decisions.
Do The Gains From AI Outweigh The Costs?
Some industry advocates argue that AI’s energy consumption isn’t as catastrophic as headlines suggest. Some groups have challenged ‘alarmist’ projections, claiming that AI’s current contribution of ‘just’ 0.02% of global energy consumption isn’t a cause for concern.
Proponents also highlight AI’s supposed environmental benefits. There are claims that AI could reduce economy-wide greenhouse gas emissions by 0.1% to 1.1% through efficiency improvements. Google reported that five AI-powered solutions removed 26 million metric tons of emissions in 2024. The optimistic view holds that AI’s capacity to optimize everything from energy grids to transportation systems will more than compensate for its data center demands.
However, recent scientific analysis reveals these arguments underestimate AI’s true impact. MIT found that data centers already consume 4.4% of all US electricity, with projections showing AI alone could use as much power as 22% of US households by 2028. Research indicates AI-specific electricity use could triple from current levels annually by 2028. Moreover, Harvard research revealed that data centers use electricity with 48% higher carbon intensity than the US average.
Advice For Sustainable AI Use In Web Design
Despite the environmental costs, AI’s use in business, particularly web design, isn’t going away anytime soon, with 70% of large businesses looking to increase their AI investments to increase efficiencies. AI’s immense impact on productivity means those not using it are likely to be left behind. This means that environmentally conscious businesses and designers must find the right balance between AI’s environmental cost and the efficiency gains it brings.
Make Sure You Have A Strong Foundation Of Sustainable Web Design Principles
Before you plug in any AI magic, start by making sure the bones of your site are sustainable. Lean web fundamentals, like system fonts instead of hefty custom files, minimal JavaScript, and judicious image use, can slash a page’s carbon footprint by stripping out redundancies that increase energy consumption. For instance, the global average web page emits about 0.8g of CO₂ per view, whereas sustainably crafted sites can see a roughly 70% reduction.
Once that lean baseline is in place, AI-driven optimizations (image format selection, code pruning, responsive layout generation) aren’t adding to bloat but building on efficiency, ensuring every joule spent on AI actually yields downstream energy savings in delivery and user experience.
Choosing The Right Tools And Vendors
In order to make sustainable tool choices, transparency and awareness are the first steps. Many AI vendors have pledged to work towards sustainability, but independent audits are necessary, along with clear, cohesive metrics. Standardized reporting on energy and water footprints will help us understand the true cost of AI tools, allowing for informed choices.
You can look for providers that publish detailed environmental reports and hold third-party renewable energy certifications. Many major providers now offer PUE (Power Usage Effectiveness) metrics alongside renewable energy matching to demonstrate real-world commitments to clean power.
When integrating AI into your build pipeline, choosing lightweight, specialized models for tasks like image compression or code linting can be more sustainable than full-scale generative engines. Task-specific tools often use considerably less energy than general AI models, as general models must process what task you want them to complete.
There are a variety of guides and collectives out there that can guide you on choosing the ‘green’ web hosts that are best for your business. When choosing AI-model vendors, you should look at options that prioritize ‘efficiency by design’: smaller, pruned models and edge-compute deployments can cut energy use by up to 50% compared to monolithic cloud-only models. They’re trained for specific tasks, so they don’t have to expend energy computing what the task is and how to go about it.
Using AI Tools Sustainably
Once you’ve chosen conscientious vendors, optimize how you actually use AI. You can take steps like batching non-urgent inference tasks to reduce idle GPU time, an approach shown to lower energy consumption overall compared to requesting ad-hoc, as you don’t have to keep running the GPU constantly, only when you need to use it.
Smarter prompts can also help make AI usage slightly more sustainable. Sam Altman of ChatGPT revealed early in 2025 that people’s propensity for saying ‘please’ and ‘thank you’ to LLMs is costing millions of dollars and wasting energy as the Generative AI has to deal with extra phrases to compute that aren’t relevant to its task. You need to ensure that your prompts are direct and to the point, and deliver the context required to complete the task to reduce the need to reprompt.
Additional Strategies To Balance AI’s Environmental Cost
On top of being responsible with your AI tool choice and usage, there are other steps you can take to offset the carbon cost of AI usage and enjoy the efficiency benefits it brings. Organizations can reduce their own emissions and use carbon offsetting to reduce their own carbon footprint as much as possible. Combined with the apparent sustainability benefits of AI use, this approach can help mitigate the harmful impacts of energy-hungry AI.
You can ensure that you’re using green server hosting (servers run on sustainable energy) for your own site and cloud needs beyond AI, and refine your content delivery network (CDN) to ensure your sites and apps are serving compressed, optimized assets from edge locations, cutting the distance data must travel, which should reduce the associated energy use.
Organizations and individuals, particularly those with thought leadership status, can be advocates pushing for transparent sustainability specifications. This involves both lobbying politicians and regulatory bodies to introduce and enforce sustainability standards and ensuring that other members of the public are kept aware of the environmental costs of AI use.
It’s only through collective action that we’re likely to see strict enforcement of both sustainable AI data centers and the standardization of emissions reporting.
Regardless, it remains a tricky path to walk, along the double-edged sword of AI’s use in web design.
Use AI too much, and you’re contributing to its massive carbon footprint. Use it too little, and you’re likely to be left behind by rivals that are able to work more efficiently and deliver projects much faster.
“
The best environmentally conscious designers and organizations can currently do is attempt to navigate it as best they can and stay informed on best practices.
Conclusion
We can’t dispute that AI use in web design delivers on its promise of agility, personalization, and resource savings at the page-level. Yet without a holistic view that accounts for the environmental demands of AI infrastructure, these gains risk being overshadowed by an expanding energy and water footprint.
Achieving the balance between enjoying AI’s efficiency gains and managing its carbon footprint requires transparency, targeted deployment, human oversight, and a steadfast commitment to core sustainable web practices.
(yk)